Dynamically Disentangling Social Bias from Task-Oriented Representations with Adversarial Attack
摘要
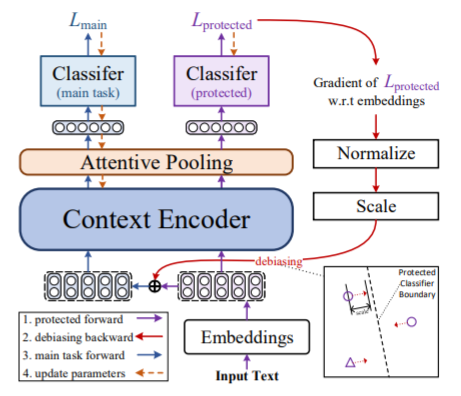
Representation learning is widely used in NLP for a vast range of tasks. However, representations derived from text corpora often reflect social biases. This phenomenon is pervasive and consistent across different neural models, causing serious concern. Previous methods mostly rely on a pre-specified, user-provided direction or suffer from unstable training. In this paper, we propose an adversarial disentangled debiasing model to dynamically decouple social bias attributes from the intermediate representations trained on the main task. We aim to denoise bias information while training on the downstream task, rather than completely remove social bias and pursue static unbiased representations. Experiments show the effectiveness of our method, both on the effect of debiasing and the main task performance.