FutureTOD: Teaching Future Knowledge to Pre-trained Language Model for Task-Oriented Dialogue
Abstract
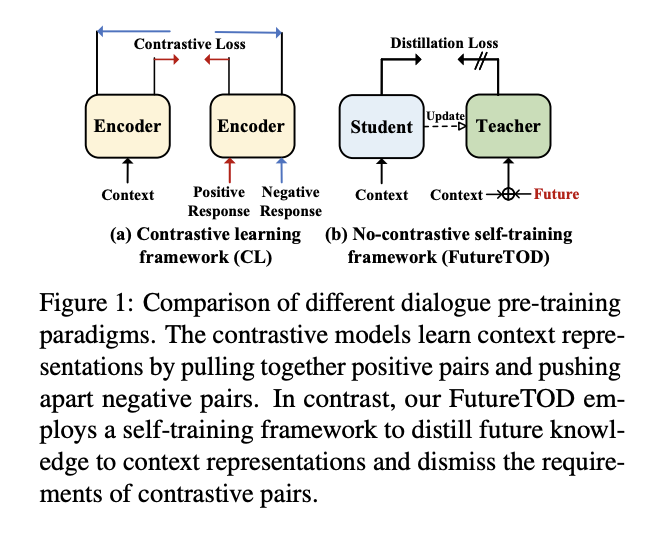
Pre-trained language models based on general text enable huge success in the NLP scenario. But the intrinsical difference of linguistic patterns between general text and task-oriented dialogues makes existing pre-trained language models less useful in practice. Current dialogue pre-training methods rely on a contrastive framework and face the challenges of both selecting true positives and hard negatives. In this paper, we propose a novel dialogue pre-training model, FutureTOD, which distills future knowledge to the representation of the previous dialogue context using a self-training framework. Our intuition is that a good dialogue representation both learns local context information and predicts future information. Extensive experiments on diverse downstream dialogue tasks demonstrate the effectiveness of our model, especially the generalization, robustness, and learning discriminative dialogue representations capabilities.
Weihao Zeng
Postgraduate Student
Yejie Wang
Postgraduate Student
Chen Zeng
Postgraduate Student
Weiran Xu
Associate Professor, Master Supervisor, Ph.D Supervisor
Information Retrieval, Pattern Recognition, Machine Learning