DolphCoder:Echo-Locating Code Large Language Models with Diverse and Multi-Objective Instruction Tuning
Abstract
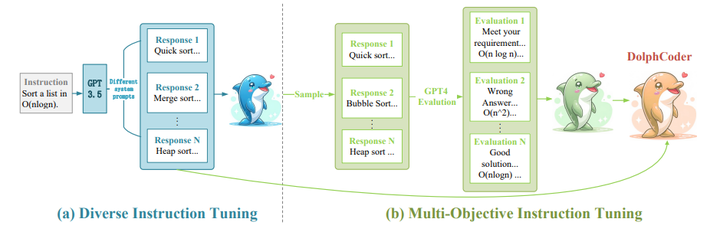
Code Large Language Models (Code LLMs) have demonstrated outstanding performance in code-related tasks. Several instruction tuning approaches have been proposed to boost the code generation performance of pre-trained Code LLMs. In this paper, we introduce a diverse instruction model (DolphCoder) with self-evaluating for code generation. It learns diverse instruction targets and combines a code evaluation objective to enhance its code generation ability. Our model achieves superior performance on the HumanEval and MBPP benchmarks, demonstrating new insights for future code instruction tuning work. Our key findings are:(1) Augmenting more diverse responses with distinct reasoning paths increases the code capability of LLMs. (2) Improving one’s ability to evaluate the correctness of code solutions also enhances their ability to create it.
Yejie Wang
Postgraduate Student
Pei Wang
Postgraduate Student
Weihao Zeng
Postgraduate Student
Muxi Diao
Postgraduate Student
Weiran Xu
Associate Professor, Master Supervisor, Ph.D Supervisor
Information Retrieval, Pattern Recognition, Machine Learning