CS-Bench:A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Abstract
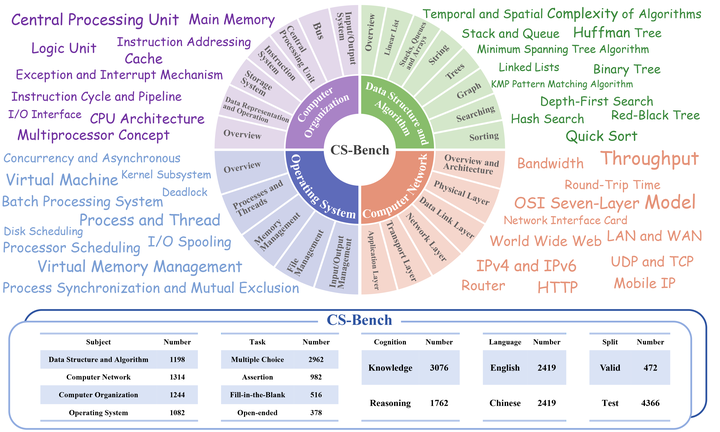
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at at https://github.com/csbench/csbench.
Xiaoshuai Song
Postgraduate Student
Muxi Diao
Postgraduate Student
Zhengyang Wang
Postgraduate Student
Zhexu Wang
Postgraduate Student
Dayuan Fu
Postgraduate Student
Weihao Zeng
Postgraduate Student
Yejie Wang
Postgraduate Student
Zhuoma GongQue
Ph.D Student
Jianing Yu
Postgraduate Student
Weiran Xu
Associate Professor, Master Supervisor, Ph.D Supervisor
Information Retrieval, Pattern Recognition, Machine Learning