BootTOD:Bootstrap Task-oriented Dialogue Representations by Aligning Diverse Responses
Abstract
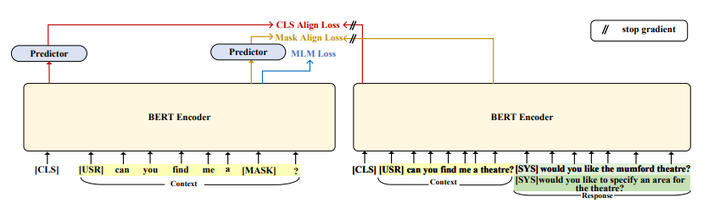
Pre-trained language models have been successful in many scenarios. However, their usefulness in task-oriented dialogues is limited due to the intrinsic linguistic differences between general text and task-oriented dialogues. Current task-oriented dialogue pre-training methods rely on a contrastive framework, which faces challenges such as selecting true positives and hard negatives, as well as lacking diversity. In this paper, we propose a novel dialogue pre-training model called BootTOD. It learns task-oriented dialogue representations via a self-bootstrapping framework. Unlike contrastive counterparts, BootTOD aligns context and context+response representations and dismisses the requirements of contrastive pairs. BootTOD also uses multiple appropriate response targets to model the intrinsic one-to-many diversity of human conversations. Experimental results show that BootTOD outperforms strong TOD baselines on diverse downstream dialogue tasks.
Weihao Zeng
Postgraduate Student
Yejie Wang
Postgraduate Student
Dayuan Fu
Postgraduate Student
Weiran Xu
Associate Professor, Master Supervisor, Ph.D Supervisor
Information Retrieval, Pattern Recognition, Machine Learning