Debiased Contrastive Learning of Unsupervised Sentence Representations
文章链接: https://arxiv.org/abs/2205.00656
代码: https://github.com/RUCAIBox/DCLR
摘要和引言
最近,对比学习被证明在改进预训练的语言模型(PLM)以获得高质量的句子表征方面是有效的。它的目的是拉近正样本以提高对齐度,同时推开不相关的负样本以提高整个表示空间的统一性。然而,以前的工作大多采用从一个batch内或从训练数据中随机抽取样本作为负样本。这样的方式可能会造成采样偏差,即不适当的负样本(如伪负样本和各向异性表征)被用来学习句子表征,这将损害表征空间的均匀性。为了解决这个问题,我们提出了一个新的框架DCLR(Debiased Contrastive Learning of unsupervised sentence Representations)来减轻这些不适当的负样本的影响。在DCLR中,我们设计了一种实例加权的方法来惩罚错误的负样本,并生成基于噪声的负样本来保证表示空间的统一性。在七个语义文本相似性任务上的实验表明,我们的方法比竞争性基线更有效。
近来,预训练语言模型被广泛用于语义表征的实现方法,在多个NLP任务上取得了显著的表现。然而,一些研究发现,由PLM产生的原始句子表征在方向上并不是均匀分布的,而是在向量空间中形成一个狭窄的锥体(Ethayarajh,2019),这在很大程度上限制了其表现力。为了解决这个问题,对比学习(Chen等人,2020)已经被采用来完善PLM产生的句子表征。它将语义上接近的样本拉到一起,以提高一致性,同时将负样本推开,以提高整个表征空间的统一性。对于正样本,以前的工作在原句上应用了数据增强策略(Yan等人,2021),以产生高度相似的变化。而由于缺乏负样本的Golden Label,负面例子通常是从批处理或训练数据中随机抽取的(例如,批内负样本(Gao等人,2021))。

虽然这种负样本的抽样方式简单方便,但它可能导致抽样偏差,影响句子表征的学习。首先,抽样的负样本很可能是虚假的负样本,而这些负样本在语义上确实与原句接近。如图1所示,根据SimCSE模型(Gao等人,2021年),给定一个输入句子,大约一半的批量内负样本与原句的余弦相似度超过0.7。通过简单地推开这些采样的负样本,很可能会伤害到句子表征的语义。其次,由于各向异性问题(Ethayarajh, 2019),采样负样本的表征来自PLMs所跨越的狭窄表征锥,不能完全反映表征空间的整体语义。因此,只依靠这些表征来学习句子表征的统一性目标是次优的。
为了解决上述问题,我们的目标是开发一种更好的对比学习方法,采用去偏的负采样策略。核心思想是改进随机抽样策略以缓解抽样偏差问题。首先,在我们的框架中,我们设计了一个实例加权的方法,以惩罚训练中的伪负样本。我们采用了一个补充模型来评估每个负样本与原句之间的相似性,然后为相似性较高的负样本分配较低的权重。通过这种方式,我们可以检测到语义上接近的假负样本,并进一步减少其影响。其次,我们根据随机的高斯噪声随机初始化新的负样本,以模拟整个语义空间内的抽样,并设计一个基于梯度的算法来优化基于噪声的负样本,以达到最不均匀的形式。通过与不均匀的基于噪声的负样本进行对比,我们可以扩展句子表征的空间,并提高表征空间的均匀性。
为此,我们提出了DCLR,这是一个针对无监督句子表征的去偏向对立学习的一般框架。在我们的方法中,我们首先从高斯分布中初始化基于噪声的负样本,并利用基于梯度的算法来更新新的负样本,同时考虑代表空间的均匀性。然后,我们采用辅助模型来产生这些基于噪声的负样本和随机抽样的负样本的权重,其中错误的负样本将受到惩罚。最后,我们通过dropout(Gao等人,2021)来增加正面的例子,并将它们与上述加权的负面例子结合起来进行对比学习。我们证明了我们的DCLR在使用BERT(Devlin等人,2019)和RoBERTa(Liu等人,2019)的七个语义文本相似性(STS)任务上优于一些竞争基线。
这项工作的目的是利用未标记的语料来学习有效的句子表征,可以直接用于下游任务,例如语义文本相似性任务(Agirre等人,2015)。给定一组输入句子X={x1, x2, . . . , xn},我们的目标是以一种无监督的方式为每个句子xi学习一个代表hi∈Rd。为了简单起见,我们用一个参数化的函数hi = f(xi)来表示这个过程。
在这项工作中,我们主要关注的是使用基于BERT的PLMs(Devlin等人,2019;Liu等人,2019)来生成句子表征。按照现有的工作(Li等人,2020年;Yan等人,2021年),我们通过我们提出的无监督学习方法在未标记的语料库上微调PLM。之后,对于每个句子xi,我们用微调后的PLM进行编码,并将最后一层的[CLS]标记的表示作为其句子表示hi。
方法
我们根据高斯分布初始化基于噪声的负样本,并迭代更新这些负样本,以达到非均匀性最大化。然后,我们利用一个辅助模型为所有的负样本(即随机抽样和基于噪声的负样本)产生权重。最后,我们将加权的负样本和增强的正面例子结合起来,进行对比学习。我们的DCLR的概述见图2。

生成基于噪声的负样本
我们的目标是在训练过程中,在PLMs的句子表征空间之外生成新的负样本,以减轻PLMs各向异性问题带来的采样偏差(Etha- yarajh,2019)。对于每个输入句子xi,我们首先从高斯分布中初始化k个噪声向量作为样本表征: $$ {\hat h_1, \hat h_2,\cdots, \hat h_k}\sim \mathcal{N}(0, \sigma^2) $$ 其中σ是标准差。由于这些向量是从这样的高斯分布中随机初始化的,因此它们在整个语义空间中是均匀分布的。通过学习与这些新的负样本进行对比,有利于句子表征的均匀性。
为了进一步提高新负样本的质量,我们考虑迭代更新负样本以捕捉整个语义空间中的非均匀性点。受VAT(Miy- ato等人,2017;Zhu等人,2020)的启发,我们设计了一个非均匀性损失最大化目标,以产生梯度来改善这些负样本。非均匀性损失被表示为基于噪声的负样本${\hat h_j}$和原句的正样本$ (h_i,h_i^+) $之间的对比损失:
$$
L_U(h_i,h_i^+,{\hat h})=-\log\frac{e^{{\rm sim}(h_i,h_i^+)/\tau_u}}{\sum_{\hat h_j \in{\hat h}}e^{{\rm sim}(h_i, \hat h_i)/\tau_u}}
$$
其中$\tau_u$是温度超参数,${\rm sim}(h_i, h_i^+)$是余弦相似度$\frac{h_i^\top h_i^+}{||h_i||\cdot||h_i^+||}$。在此基础上,对于每个负样本$\hat h_j\in{\hat h}$,我们用$t$步梯度下降法优化它
$$
\hat h_j=\hat h_j+\beta g(\hat h_j)/||g(\hat h_j)||_2\
g(\hat h_j)=\nabla_{\hat h_j}L_U(h_i,h_i^+,{\hat h})
$$
这样一来,基于噪声的负样本将被优化到句子表征空间的非均匀点。通过学习与这些负样本的对比,可以进一步提高表示空间的均匀性,这对有效的句子表示是至关重要的。
实例加权的对比学习
除了上述基于噪声的负样本,我们还遵循现有的工作(Yan等人,2021;Gao等人,2021),采用其他batch内表征作为负样本${\tilde h^-}$。然而,正如前面所讨论的,采样的负样本可能包含与正样本有相似语义的例子(即伪负样本)。
为了缓解这个问题,我们提出了一种实例加权的方法来惩罚伪负样本。由于我们无法获得真实的标签或语义相似性,我们利用一个补充模型来产生每个负数的权重。我们采用最先进的SimCSE(Gao等人,2021)作为补充模型。给定一个来自${\tilde h^-}$或${\hat h}$的负样本$h^-$和原始句子$h_i$的表征,我们利用辅助模型来产生权重:
$$
\alpha_{h^-}=\begin{cases}
0,{\rm sim}_C(h_i,h^-)\ge\phi\
1,{\rm sim}_C(h_i,h^-)<\phi
\end{cases}
$$
其中${\rm sim}_C$是辅助模型评估的余弦相似度。这样一来,与原句的语义相似度较高的负样本将被视为伪负样本,并被赋予0的权重以示惩罚。 基于这些权重,我们用去掉交叉熵的对比学习损失函数来优化句子表征,即
$$
L=-\log\frac{e^{{\rm sim}(h_i,h_i^+)/\tau}}{\sum_{h^- \in{\hat h}\cup{\tilde h^-}}e^{{\rm sim}(h_i, h^-)/\tau}}
$$
如上所述,我们的方法旨在重新消除关于负面的抽样偏差的影响,并且对各种正样本的增强方法(例如,token cutoff和dropout)是不关心的。由于基于噪声的负样本是从高斯分布中初始化的,并不对应于真实的句子,因此它们是高度自信的负样本,以扩大表示空间。通过学习与它们的对比,对比目标的学习将不会受到来自PLMs的各向异性表征的限制。因此,句子表征可以跨越更广泛的语义空间,表征语义空间的统一性也可以得到改善。
此外,我们的实例加权方法还缓解了随机抽样策略造成的伪负样本问题。在补充模型的帮助下,那些与原句语义相似的伪负样本句子将被检测出来并受到惩罚。
实验
按照以前的工作(Kim等人,2021;Gao等人,2021),我们对七个标准的语义文本相似度任务(Semantic Textual Similarity,STS)进行了实验。对于所有这些任务,我们使用SentEval工具包(Conneau and Kiela, 2018)进行评估。
我们在7个STS任务中评估了我们的方法。STS 2012-2016(Agirre等人,2012,2013,2014,2015,2016),STS Benchmark(Cer等人,2017)和SICK-Relatedness(Marelli等人,2014)。这些数据集包含成对的两个句子,其相似度分数从0到5进行标注。黄金标注和句子表征预测的分数之间的相关性由Spearman关联度来衡量。根据以往工作的建议(Gao等人,2021;Reimers和Gurevych,2019),我们直接计算所有STS任务的句子嵌入之间的余弦相似度。
基线方法
我们将DCLR与竞争性的无监督句子表示学习方法进行比较,包括非BERT和基于BERT的方法。
- GloVe:把GloVe的词嵌入平均作为句子表征。
- USE:一个Transformer模型,训练目标是在一段话中重建周围的句子。
- CLS,Mean, First-Last AVG分别采用[CLS]嵌入、token表征的平均池化、第一层和最后一层的平均表征作为句子表征。
- Flow 将平均池化应用在各层表征上,并将输出映射到高斯空间上作为句子表征。
- Whitening使用whitening操作来完善表征,降低维度。
- Contrastive(BT)使用对比学习与回译进行数据增强,以提高句子的代表性。
- ConSERT探讨了各种文本增强策略,用于句子表征的对比学习。
- SG-OPT提出了一种具有自我引导机制的自适应学习方法,以改善PLM的句子嵌入。
- SimCSE提出了一个利用dropout进行数据增强的对比学习框架。
使用从维基百科中随机抽取的1,000,000个句子作为训练语料库。
实验分析
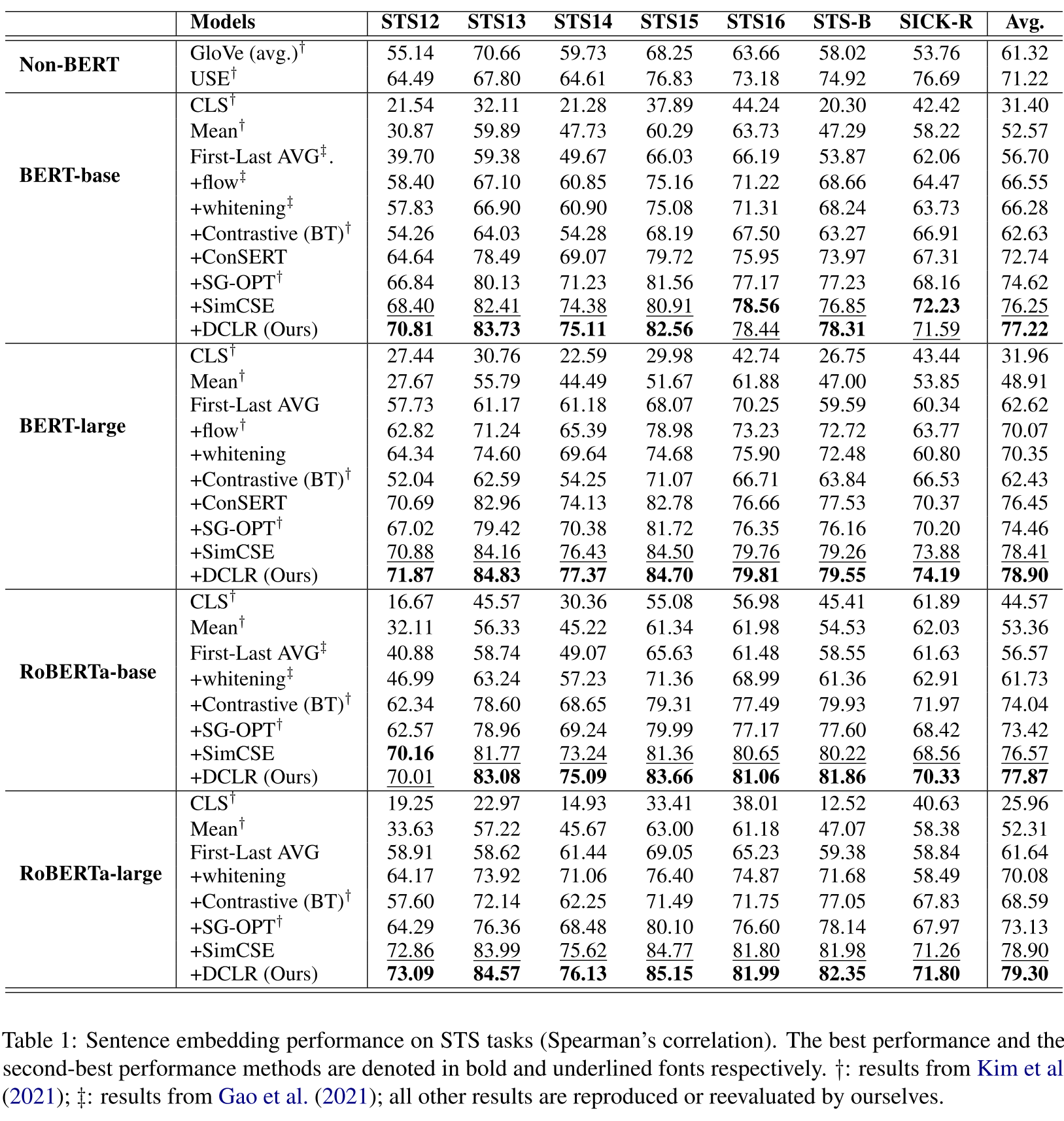
为了验证我们的框架在PLM上的有效性,我们选择BERT-base和RoBERTa-base作为基础模型。表1显示了不同方法在七个STS任务上的结果。根据这些结果,我们可以发现,非BERT方法(即GloVe和USE)大部分都比基于PLM表示的基线(即CLS,Mean和First-Last AVG)要好。原因是直接利用PLM的原始表征很容易受到各向异性的影响。在非BERT方法中,USE优于Glove。一个潜在的原因是USE使用Transformer模型对句子进行编码,这比简单的平均GloVe 嵌入更有效。
对于其他基于PLM的方法,首先,我们可以看到flow和whiteening取得了类似的结果,并在一定程度上超过了基于原始表征的方法。这两种方法采用了特定的改进策略来完善PLMs的表征。第二,基于对比学习的方法在大多数情况下优于其他基线。对比学习可以提高语义相关的正样本对之间的一致性和使用负样本的表征空间的均匀性,从而产生更好的句子表征。此外,SimCSE在所有基线中表现最好。这表明dropout是一种比其他方法更有效的正样本增强方法,因为它很少伤害到句子的语义。
最后,DCLR在大多数情况下都比所有的基线表现得更好,包括基于对比学习的方法。由于这些方法大多利用随机抽样的负样本(如batch内负样本)来学习所有句子表征的统一性,它可能会导致抽样偏差,如假负样本和各向异性的表征。与这些方法不同的是,我们的框架采用了一种实例加权的方法来惩罚错误的负样本,并采用了一种基于梯度的算法来生成基于噪声的负样本。这样一来,采样偏差问题可以得到缓解,我们的模型可以更好地学习均匀性,以提高句子表征的质量。
扩展实验
由于我们提出的DCLR是一个通用的框架,主要集中在无监督的句子代表的锥形学习的负采样上,它可以应用于其他依靠不同的正样本增强策略的方法。因此,在这一部分中,我们进行了实验,以检验我们的框架是否能够通过以下积极的数据增强策略带来改进:(1)Token Shuffling,随机打乱输入句子中的token顺序;(2)Feature/Token/Span Cutoff(Yan等人,2021),随机置零输入中的特征/token/token span;(3)Dropout,类似于SimCSE(Gao等人,2021)。

如图3所示,我们的DCLR可以提高所有这些增强策略的性能,它显示了我们的框架与各种增强策略的有效性。此外,在所有的变体中,Dropout策略取得了最好的性能。这表明Dropout是一种更有效的增强高质量正样本的方法,也更适合于我们的方法。
消融实验
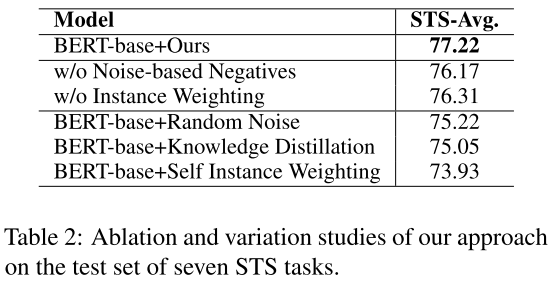
如表2所示,删除每个组件都会导致性能下降。这表明,在我们的框架中,实例加权法和基于噪声的负样本都很重要。但是,去除实例加权方法会导致更大的性能下降。其原因可能是错误的负样本对句子表示学习有较大的影响。此外,我们准备了三种变体进行进一步的比较:(1)Random Noise直接生成基于噪声的负样本,而没有基于梯度的优化;(2)Knowledge Distillation(Hinton等人,2015)利用SimCSE作为教师模型,在训练期间将知识提炼到学生模型中;(3)Self Instance Weighting采用模型本身作为补充模型来生成权重。从表2中,我们可以看到这些变化并没有像原始的DCLR那样表现良好。这些结果表明,第4节中提出的设计更适合我们的DCLR框架。
均匀性分析
均匀性是句子表征的一个理想特性,描述了表征的均匀分布程度。为了验证我们框架的均匀性的改善,我们比较了DCLR和SimCSE在训练期间使用BERT-base的均匀性损失曲线。
按照SimCSE(Gao等人,2021年),我们利用以下函数来评估均匀性: $$ \ell_{uniform}\triangleq \mathop{\mathbb E}_{x_i,x_j \sim p_{data}}\exp(-2||f(x_i)-f(x_j)||^2) $$ 这个损失的数值越小,说明均匀性越好。如图4所示,几乎在整个训练过程中,DCLR的均匀性损失要比SimCSE的低得多。此外,我们可以看到,随着训练的进行,DCLR的均匀性损失下降得更快,而SimCSE的均匀性损失则没有明显的下降趋势。这可能是因为我们的DCLR在表示空间之外对基于噪声的负样本进行了采样,这可以更好地提高句子表示的均匀性。
少样本设置下的表现
为了验证DCLR在数据稀缺情况下的可靠性和稳健性,我们使用BERT-base作为骨干模型进行了少样本实验。我们通过从100%到极小规模(即0.3%)的不同数量的可用训练数据训练我们的模型。我们报告了在STS-B和SICK-R任务上评估的结果。
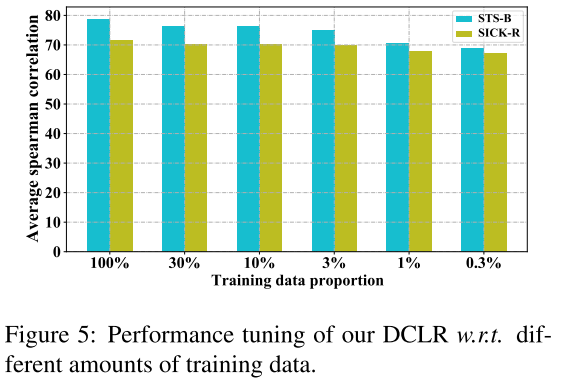
如图5所示,我们的方法在不同比例的训练数据下取得了稳定的结果。在数据比例为0.3%的最极端设置下,我们的模型在STS-B和SICK-R上的性能分别只下降了9%和4%。这些结果揭示了我们的方法在数据稀缺的情况下的稳健性和有效性。这种特性在现实世界的应用中是很重要的。
总结
在本文中,我们提出了DCLR,一个用于无监督的去偏句子表征学习学习框架。我们的核心思想是缓解由随机负抽样策略引起的抽样偏差。为了实现这一目标,在我们的框架中,我们采用了一种实例加权的方法来惩罚训练过程中的错误负样本,并产生了基于噪声的负样本,以减轻各向异性的PLM衍生代表的影响。在七个STS任务上的实验结果表明,我们的方法优于几个有竞争力的基线。在未来,我们将探索其他方法来减少句子表征的对比性学习中的偏差。此外,我们还将考虑将我们的方法用于多语言或多模态表征学习。