Recent research overview(2022.04.08)
ADPL: Adversarial Prompt-based Domain Adaptation for Dialogue Summarization with Knowledge Disentanglement
Authors
赵璐璐1, 郑馥嘉1, 曾伟豪, 何可清, 耿若彤,江会星,武威, 徐蔚然2
Conference
SIGIR 2022 Full Paper
Introduction
领域自适应是机器学习中的一个基本任务。在本文中,我们研究对话摘要任务中的领域迁移问题,试图借助源域的有标注数据迁移到无标注或少标注的目标域,进而提升低资源目标域下对话摘要的生成效果,可用于解决实际场景中小业务数据匮乏的挑战。传统的对话摘要领域迁移方法往往依赖于大规模领域语料,借助于预训练来学习领域间知识。该方法的缺点是实际语料收集难,对算力要求高,针对每一个目标域都需要进行耗时的预训练过程,效率低。因此,本文从微调的角度出发,提出了一种轻量级的解耦知识迁移方法ADPL,无需大规模的预训练过程,仅仅利用源域数据和少量的无标注目标域数据,即可实现高质量的对话摘要生成。具体来说,我们基于prompt learning的思想,针对对话摘要任务中的领域迁移问题,提出了三种特定的prompt结构:domain-invariant prompt (DIP), domain-specific prompt (DSP), 和task-oriented prompt (TOP),其中 DIP 用来捕获领域间的共享特征,DSP用来建模领域特有知识,TOP用来促进生成流畅的摘要。在训练中,我们仅仅更新这些prompt相关的参数就可以实现领域间知识的解耦和迁移,相比较之前的预训练方法,训练高效环保,对机器的显存要求显著降低。同时,我们基于两个大规模的对话摘要数据集QMSum和TODSum构建了对话摘要领域迁移评测集,在两个评测集上取得了一致的最优效果,实验结果和消融分析都证明了本文提出方法的有效性。
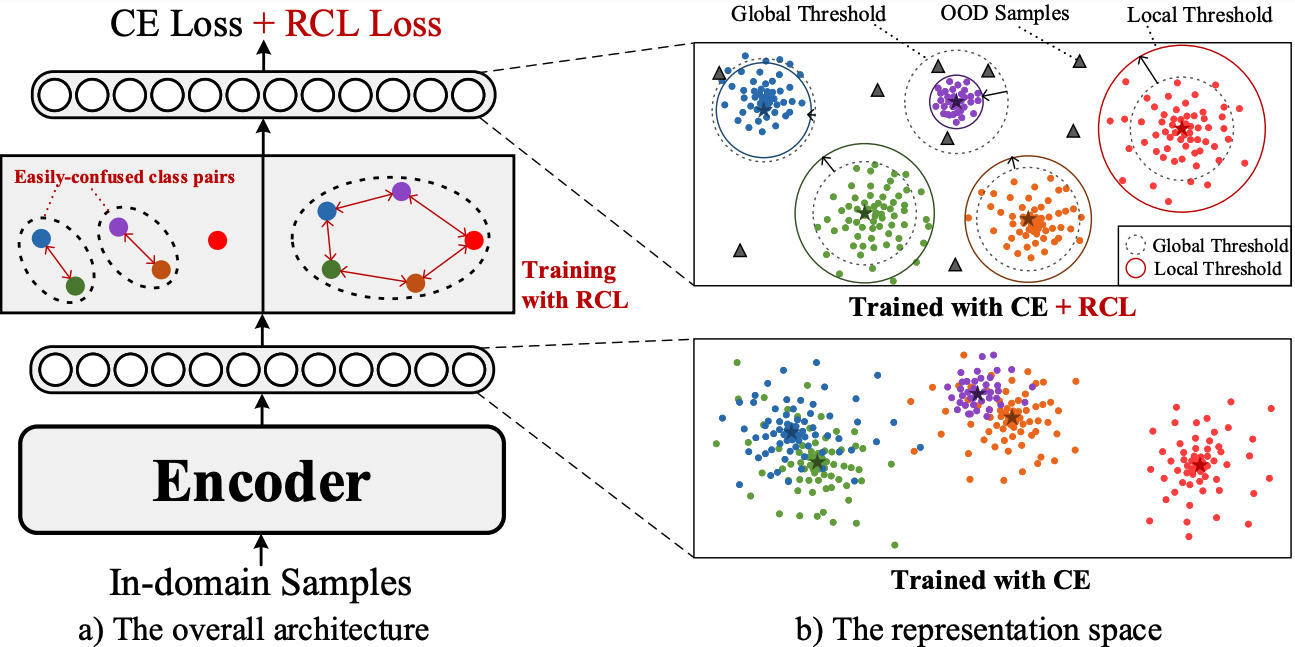
Revisit Overconfidence for OOD Detection: Reassigned Contrastive Learning with Adaptive Class-dependent Threshold
Authors
吴亚楠1, 何可清1, 严渊蒙, 高琪翔, 曾致远, 郑馥嘉, 赵璐璐,江会星,武威, 徐蔚然2
Conference
NAACL 2022 Main Conference, Long Paper
Introduction
在面向任务的对话系统中,域外意图(out-of-domain, OOD)检测是必不可少的。它旨在检测用户查询是否超出预定义意图范围(in-domain, IND),以避免执行错误的操作。由于OOD意图标注的复杂性,大多数工作都集中在无监督OOD检测上,即没有标记OOD数据,只有标记IND数据。而当前无监督域外检测方法均忽略了域外检测中的关键性挑战——神经网络的过自信问题。
在本文中,我们对过自信问题进行了深入分析,并将其拆解为两方面:过自信OOD和过自信IND。基于此,我们分别提出了一种新的重分配对比学习(RCL)来区分语义相似的IND类别之间的意图表示,以缓解过自信OOD问题,以及一种自适应的类局部阈值机制来区分相似的IND和OOD样本,以缓解过自信IND问题。
具体来说,对于过自信OOD问题,我们首先使用预训练的意图分类器在易混淆的IND类型中构建hard对比对(其中,具有相同真实标签但不同的预测标签称为hard positive pair,不同真实标签但相同预测标签称为hard negative pair),然后,基于构建的对比对训练一个新的模型,并通过监督对比学习来学习相似IND类别的鉴别性意图表示;对于过自信IND问题,不同于传统MSP、GDA使用单一全局阈值的方式,为考虑IND和OOD类别之间的关联性,我们为每个意图类别自适应赋予一个独立阈值,有效区分语义高度相似的IND和OOD样本,缓解过自信OOD问题。多个数据集上实验和分析证明了本文提出方法的有效性。
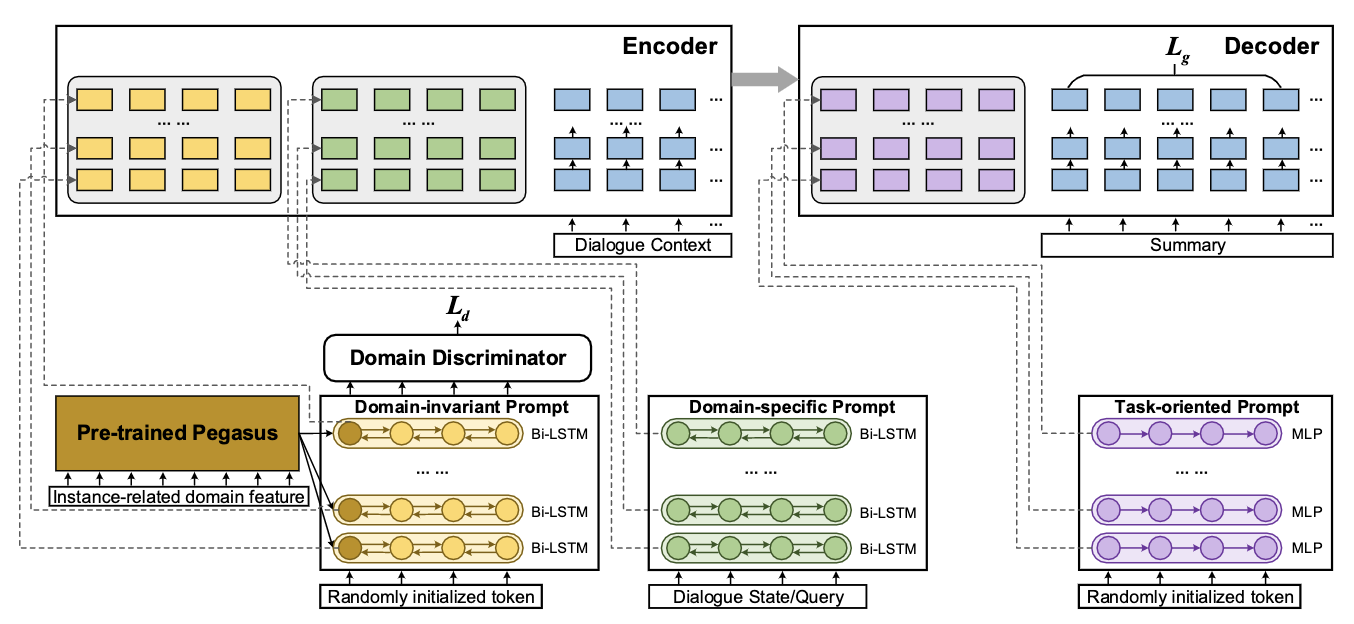
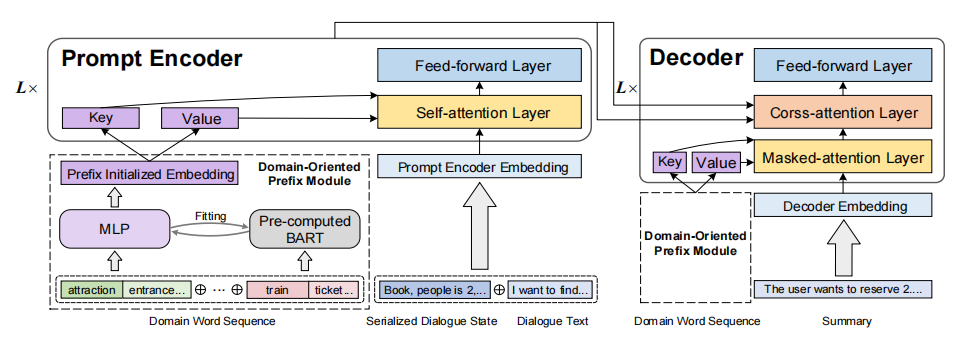
Domain-Oriented Prefix-Tuning: Towards Efficient and Generalizable Fine-tuning for Zero-Shot Dialogue Summarization
Authors
赵璐璐1, 郑馥嘉1, 曾伟豪, 何可清, 徐蔚然2,江会星,武威, 吴亚楠
Conference
Introduction
现实生活中经常面临到新领域中数据标注稀缺的问题,为新领域进行标注耗时耗力,因此利用有限的源域注释数据为目标域开发低资源对话摘要模型至关重要。当前的生成式对话摘要方法缺乏对新领域的泛化能力,而现有的在摘要领域自适应问题上的研究通常是依赖于大规模的二次预训练。
为了探索对话摘要领域自适应的轻量级微调方法,在本文中,我们提出了一种高效且可泛化的面向领域的Prefix-tuning模型(Domain-Oriented Prefix-tuning,DOP),在冻结的预训练模型的基础上,结合连续的prefix和离散的prompt表示,提高模型的领域自适应能力。具体来说,我们使用无监督 LDA提取的领域词来初始化连续提示向量,以获得前缀模块的初始参数和表示。我们还添加了一个面向领域的键值对前缀序列来增强经典注意力层,以交互方式获取知识并实现优化。除此之外,我们使用dialogue state和query作为离散prompt,引导模型关注对话中关键内容并增强对新领域的泛化能力。
我们在两个多域对话摘要数据集 TODSum 和 QMSum 上进行零样本迁移实验并建立领域自适应benchmark, 充分的实验和定性分析证明了我们方法的有效性。
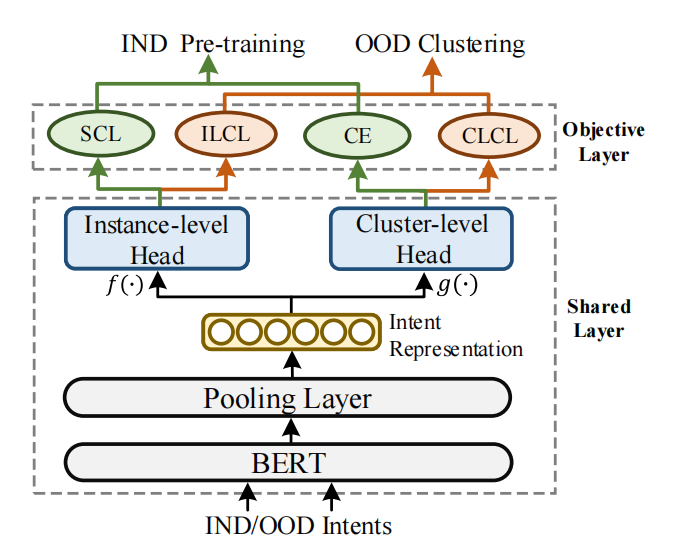
Disentangled Knowledge Transfer for OOD Intent Discovery with Unifified Contrastive Learning
Authors
牟宇滔1, 何可清1, 吴亚楠1, 曾致远, 徐红,江会星,武威, 徐蔚然2
Conference
Introduction
本文研究域外(OOD)意图发现任务,该任务旨在将新出现的未知意图的样本按意图语义聚成不同类簇,这有助于任务型对话系统发展新的技能。不同于传统的文本聚类任务,域外意图发现需要考虑如何利用已知的域内(IND)意图类别的先验知识,帮助新意图的聚类。因此相关方法都遵循一个两阶段框架:IND预训练和OOD聚类。其中的关键挑战在于如何将IND先验知识迁移到OOD聚类上。之前的方法普遍存在一个问题,将IND预训练过程当作分类任务,采用一个交叉熵分类损失,模型学习到如何分类IND样本,但是下游我们需要对OOD聚类。两个阶段不同的学习目标使得存在一个天然的语义鸿沟,使得IND到OOD的知识迁移变得困难。此外,我们观察到之前的方法只迁移BERT输出的一个共享意图表征,考虑到表征具有高度耦合性,这样一个表征可能不利于OOD聚类。例如,在IND预训练的编码器中存在实例级(instance-level)和聚类级(class-level)的知识,解耦不同级别的知识有助于更好地知识迁移。为了解决这样的问题,我们建立了一个统一的多头对比学习框架,并在此基础上提出了一个新颖的解耦知识迁移方法(DKT),以便迁移解耦IND意图知识用于OOD聚类。我们意在弥合IND预训练和OOD聚类两个阶段的语义鸿沟。两个基准数据集的实验和分析显示了我们方法的有效性。