Measure and Improve Robustness in NLP Models: A Survey
本文是一片关于NLP模型鲁棒性的综述,统一地介绍了如何定义、衡量和提升NLP模型的鲁棒性。
NLP模型鲁棒性的定义
模型在$(x, y) \sim \mathcal{D}$上训练,在$(x', y')\sim \mathcal{D'} \ne \mathcal{D}$ 上测试,可以用模型在$\mathcal{D'}$上的性能(如准确率)衡量模型的鲁棒性。
可以粗略地将现有的模型鲁棒性的文献分为两类:$\mathcal{D'}$是对输入合成扰动,或者 $\mathcal{D'}$是自然发生的分布转移。
对对抗攻击的鲁棒性
对抗攻击是指故意精心制造噪声来欺骗模型做出错误的预测,之前在CV领域被广泛探索, 后来扩展到NLP领域。对抗样本的生成主要建立在这样一个观察之上,即我们可以生成对人类有意义的样本(例如,通过用人类察觉不到的变化干扰样本),同时改变对该样本的模型预测。 对抗攻击主要建立在人类可以理解大量同义词或者忽略字母的确切顺序,但机器不能。
现在大多数CV研究都做了一个相对简单的假设,即在$x$上加有界摄动得到的$x'$的金标应该保持不变, 即$y'=y$,模型的鲁棒行为应该是$f(x')=f(x)$。其中的摄动可以是token和字符的交换,释义, 不改变语义的对抗规则,或者添加干扰因素。
然而,这个标签不变的假设可能并不总是成立的,有人研究了几种现有的文本扰动技术,但发现 一大部分扰动样本都改变了标签(尽管是在保留标签的假设下)或者结果的标签在人类标注者中 存在高度分歧。
还有一个相似的概念是语义保留,是指$(x, x')$之间的语义是不变的,而上面的标签保留是指 $(y, y')$是不变的。
对分布转移的鲁棒性
现有的鲁棒性定义更接近域泛化或OOD泛化的概念,其中测试集(不管有无标签)都是在训练的时候 不可获取的。 在NLP背景下,对自然分布转移的鲁棒性也意味着模型的性能不会因为语法错误、方言、说话者和 语言的差异或者为同一任务不同领域新收集的数据集而降低。
另一个密切相关的研究方向是公平性,例如,在指代消解、职业分类、神经机器翻译等任务中观察到了性别刻板印象或偏差。
联系和共同主题
合成 上述两个分类都可以归为一个框架中,即$\mathcal{D'}$代表合成分布转移(通过对抗攻击)或自然分布转移。 两者的联系仍有待探索。在CV领域,有研究表面对合成分布转移的鲁棒性可能对自然分布转移鲁棒性贡献 很少甚至没有贡献。
为了更好地理解模型为什么缺乏鲁棒性,一些现有的工作认为这是因为模型有时利用虚假的特征和标签之间的 关系,而非真正的关系。其中虚假的特征通常定义为并不真正影响任务标签的特征。它们和任务标签有联系,但是不能转移到更加有挑战性的测试条件或OOD数据。一些其他的工作将其定义为适用于大多数情况但不适用于一般情况的规则。这些虚假的关系有时被称为数据集偏差或群体转移。此外,有证据表明,控制模型在虚假特征下的学习将提高模型在分布转移中的性能。还有学者讨论了对抗鲁棒性和伪特征学习之间的联系。还有人通过将模型在分布转移或对抗性攻击中缺乏鲁棒性的原因归因于模型对虚假特征的学习,提出了连接这些领域的理论性的讨论。
此外,在某些应用中,模型的鲁棒性也可以与模型的不稳定性或者模型的不确定度估计很差联系起来。 对于此,有人提出了贝叶斯方法、基于dropout和基于组装的实现方法。最近,Ovadia等人已经证明,模型的不确定性估计可能在分配转移下显著降低,并呼吁应当通过对OOD数据给出更低的不确定性估计,确保 模型“知道它什么时候不知道”。
识别非鲁棒
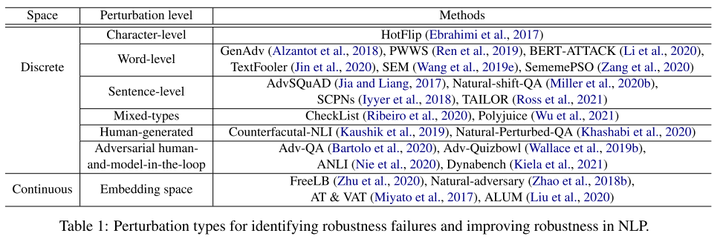
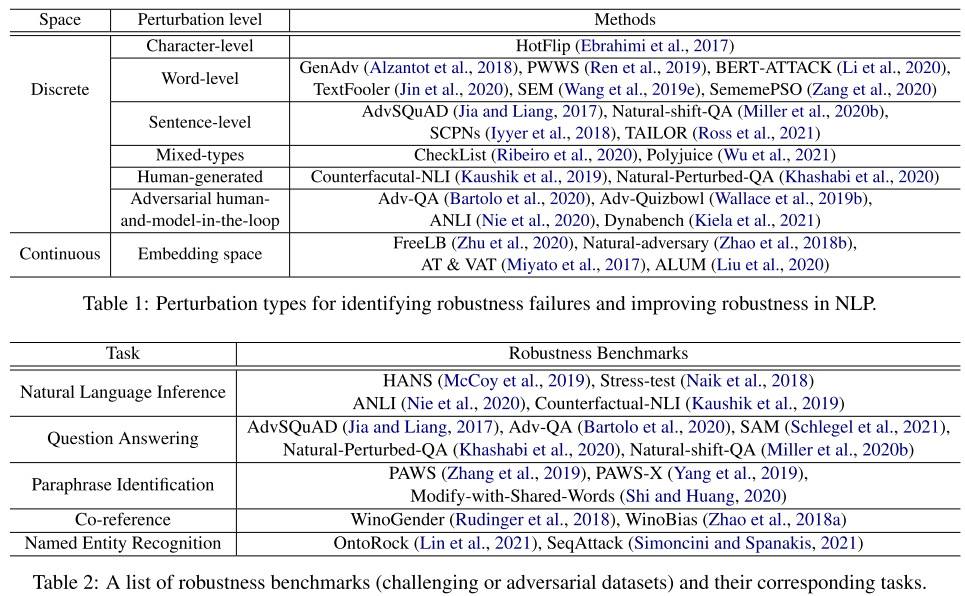
随着鲁棒性在自然语言处理文献中得到越来越多的关注,各行各业都提出了识别自然语言处理模型鲁棒性失效的方法。现有工作可以根据故障的识别方式大致分类,其中很大一部分工作依赖于人类先验和对现有NLP模型的错误分析,其他一些工作线采用基于模型的方法。为了更准确地度量自然语言处理模型的鲁棒性,通常将识别出的鲁棒性失效模式组织成具有挑战性/对抗性的基准数据集。表1展示了用于识别模型鲁棒性失效的常用扰动类型(数据集),在表2中,我们总结了每个NLP任务的常见鲁棒性基准(benchmark)。
人类先验和错误分析驱动的
按任务分,包括NLI(Natural Language Inference),QA和神经机器翻译。
NLI
Naik等人抽样错误分类的例子,并分析其潜在的错误来源,然后将其归类为常见错误原因的类型。这些错误类型将作为构建压力测试集的基础,以进一步评估NLI模型是否具有做出真实推理决策的能力,还是仅仅依赖于复杂的模式匹配。Gururangan等人发现,目前的NLI模型很可能仅依靠假设来识别标签,而Poliak等人提供了类似的补充,即我们采用仅假设的模型可以优于一组强基线。
QA
有人提出通过在段落末尾串联一个敌对的干扰句来生成敌对的QA例子。Miller等人为斯坦福问答数据集(SQuAD)构建了四个新的测试集,并发现大多数问答系统未能推广到这一新的数据。他们也希望对自然分布转移进行新的评估指标。
机器翻译
Belinkov和Bisk发现,当面对嘈杂数据时,基于字符的神经机器翻译(NMT)模型是脆弱的,很容易不稳定,其中噪音(例如,打字、拼写错误等)是使用可能的词汇替换合成的。使用包含人工引入语法错误的句子或随机合成噪音的增强训练数据可以使系统对这种虚假模式更加稳健。另一方面,有人展示了另一种方法,通过限制字符的输入空间,使模型有可能感知数据输入错误和拼写错误。
基于模型的
这种方法有的是任务不确定的,有的是输入不可知的。 这种方法通过训练一个额外的模型来捕获偏差。例如,在视觉问题回答中,Clark等人训练一个朴素模型来预测基于问题的原型答案,而不考虑上下文;Utama等人提出学习一个仅使用数据集偏差相关特征的有偏模型。此外,Culotta的目标是通过训练分类器来识别模型中的捷径,从而从人类标注的例子中更好地区分虚假的相关性和真实的相关性。
提升模型鲁棒性
根据人工干预的位置和方式,这些方法可以分为数据驱动的、基于模型和训练方案的、基于归纳先验和最后的因果干预。
数据驱动(数据增强)
如Mixup, MixText, CutOut, AugMix, HiddenCut。这类缓解方法是在数据层面上操作的,往往很难解释如何以及为什么起作用。
基于模型和训练策略
预训练
最近的研究表明,预训练是提高NLP模型非分布鲁棒性的有效方法,这可能是因为其自我监督的目标,以及使用了大量不同的训练前数据,这些数据鼓励从少量的测试样本中归纳出一般化的结果,从而抵消了虚假的相关性。有研究显示一些其他因素也可以促进稳健的准确性,包括更大的模型尺寸、更多的微调数据和更长的微调。Taori等人在视觉领域也进行了类似的观察,其中作者发现,与现有文献提出的各种鲁棒性干预相比,使用更大、更多样化的数据集的训练在多个情况下提供了更好的鲁棒性。
更好地利用少数群体的样本训练
还有一些工作建议通过更好地使用少数例子来简化模型,例如,在训练分布中代表性不足的例子,或更难学习的例子。例如,Yaghoobzadeh等人提出,首先根据全部数据对模型进行微调,然后只对少数例子进行微调。一般来说,强调样本子集的训练策略对模型来说特别难学习,有时也被称为DRO(distributional robust optimization,分布式鲁棒优化)组。DRO的扩展主要是讨论如何识别被认为是少数样本。例如,Nam等人通过强调模型的早期决策来训练另一个模型;Lahoti等人也使用另一个模型来识别对主模型具有挑战性的样本;Liu等人提出通过对在第一次训练时损失较大的少数例子增加权重,对模型进行第二次训练。
基于归纳的实现方法
另一个思路是引入归纳偏差(即正则化假设空间),迫使模型丢弃一些虚假的特征。这与基于人先验的识别方法密切相关,因为这些人的先验知识通常可以用额外的正则化器来重新制定训练目标。为了实现这一目标,通常需要首先构造一个侧组件来通知主模型有偏差的特征,然后根据侧组件来正则化主模型。这个侧组件的构造通常依赖于失调特征是什么的先验知识。然后,可以建立相应的方法来应对特征。类似地,Clark等人提出用一个显式捕获偏差的模型进行集成,其中主模型与这个仅偏差(bias-only)模型一起训练,这样主模型就不被鼓励使用偏差。最近的工作表明,通过更好地校准仅偏差模型,基于集成的方法可以进一步改进。
总之,这种方法大概是在不同的领域/分布中训练小的经验损失,以迫使模型对特定领域的虚假特征不变。
干预因果关系
Srivastava利用人类对因果关系的常识知识,以潜在的未测量变量来增加训练样本,并提出了一种基于DRO的方法,以使模型对分布转移具有鲁棒性。Veitch等人提出学习依赖于数据因果结构的估计反事实不变量预测,并表明它可以帮助减少文本分类中的虚假相关性。
提升鲁棒性策略的联系
大体可分为3类:
- 利用大量数据预训练模型
- 学习跨领域/环境的不变表示或预测
- 基于具体的虚假/偏见模式的数据
有趣的是,统计研究表明,许多缓解方法都有相同的鲁棒机器学习泛化误差界。