《Ordered Neurons:Integrating Tree Structures into Recurrent Neural Networks》阅读笔记
Conference from: ICLR 2019
Paper link: [OpenReview] [PDF]
本文拟解决的问题
自然语言具有显著的层级结构特征,小的语言单元(例如短语)被嵌套包含在大的语言单元(例如从句)中,这样的层级结构往往能够通过类似一棵树的形式(语法分析树)来表示出来,如下图:

作者认为人类的大脑也能隐式地捕捉到自然语言的这种内在特征,原因在于小孩子在习得语言的时候并没有被提供标注了的语法树。这一发现启发了作者,是否能通过一些方式使得神经网络模型也能隐式学习到这种自然语言的内在层级结构特征。
问题的意义
从实际的角度出发,把自然语言的树形结构集成到神经网络语言模型中有如下几个好处:
- 能够获取自然语言不同层级上的抽象表示
- 能够帮助建模不同语言成分之间的关系,同时能帮助解决长效依赖问题(通过在梯度反传的时候提供shortcuts)
- 能够帮助模型有一个更好的归纳偏向(inductive bias),提高模型的泛化能力,使之能够用更少的数据达到相同水平
相关工作
建模自然语言的树形结构的一种直观方式就是:通过标注数据/外部的语法分析器来有监督地训练模型,要求模型正确预测给定自然语言的分析树结构。作者认为这个方法有以下缺点:
- 很少的语言能获取到这样的标注数据/外部的语法分析器
- 在一些领域,这样的语法规则很可能不准(例如在推特中)
- 自然语言在使用过程中会变化,所以语法规则也相应地需要演化
另一个领域是语法归纳(grammar induction)任务,旨在通过无监督的语料学习到语法特征。作者任务许多此类尝试过于复杂且难以实现,有些工作引入了一些琐碎的结构(例如:最左分析树 or 最右分析树),或是难以训练(例如:使用了强化学习)。
另一种方法是采用不同时间尺度的循环(varying time-scales of recurrence)来捕捉层级结构,最近的方法有Clockwork RNN,它通过对RNN的神经元分段,划分成不同的时间尺度,其缺点(相比本文)就是这里的层级深度是预定义好的。另一篇和本文很相似的论文,采用nested dropout:每个神经元dropped不是独立、随机的,而是每当一个神经元dropped,所有排在这个神经元后面的所有神经元都会被dropped。
此外,在原文中还提到了以下观点以及相关的支持论文:
- RNNs能够高效的对自然语言建模
- RNNs存在的某些不足之处(长效依赖、模型泛化、处理否定表述)
- LSTMs能够隐式地对自然语言中的树形结构建模
本文提出的模型
其中包含的直觉
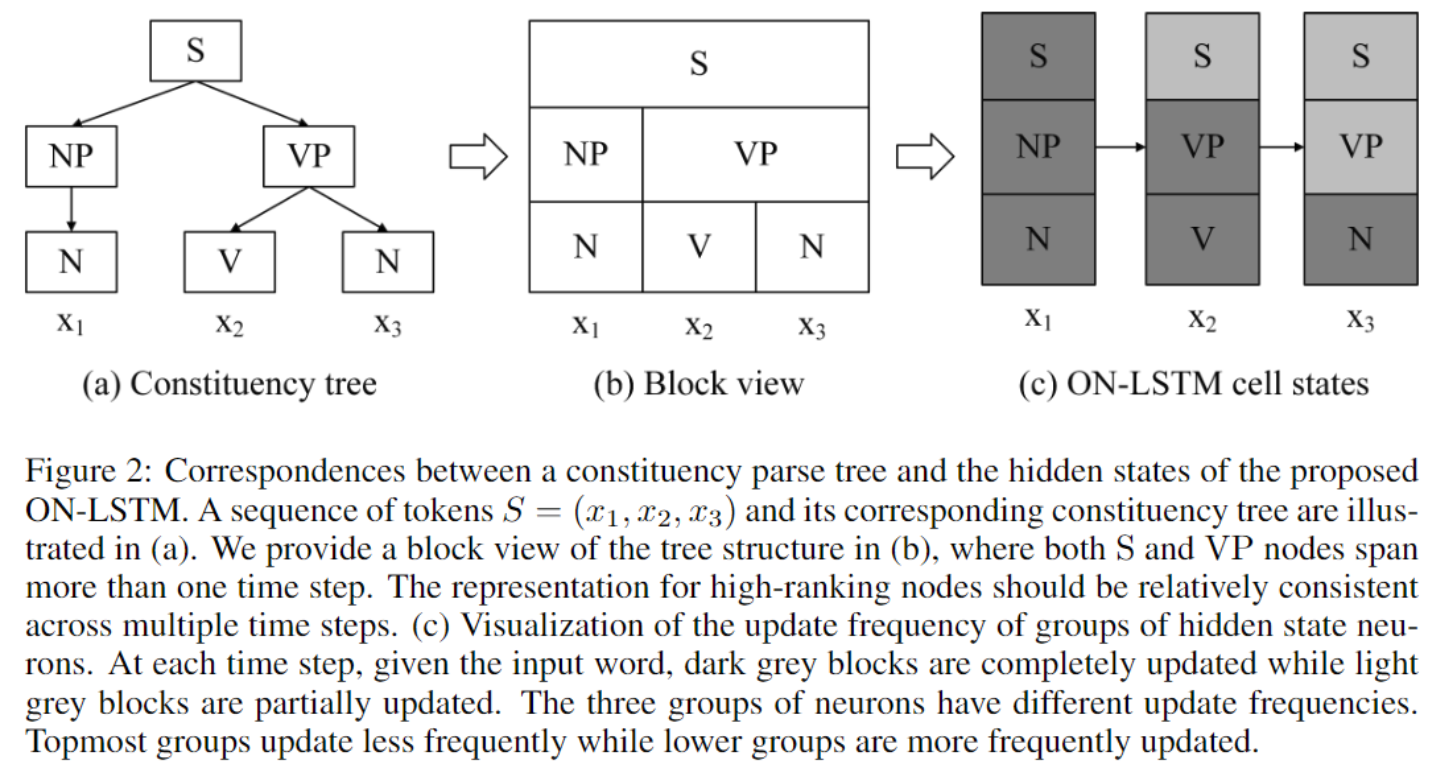
给定一个tokens构成的序列$S=(x_1, …, x_T)$,以及与之对应的语法分析树,如图(a),其中NP为名词性短语,VP为动词性短语,模型的目标就是通过给定的序列去推断句子内在的树形结构。对于LSTM而言,每个时间步$t$的输出$h_t$,理想情况下应该包含结点$x_t$到分析树树根$S$路径上的所有信息。如图(c),给出了在$t$时刻涉及$x_t$的所有语言成分,这些语言成分就是应该(在理想情况下)全部被包含在$h_t$之中的。
所以一个直观的想法就是:可以使用隐层状态中的一组神经元去代表分析树中的某一个句子成分。然而尽管隐层向量的的维度是固定的,但从叶子结点到根结点的路径中的每个句子成分可能会随句子和时间步的不同,其长度有所变化。所以一个比较好的方法就是让模型动态地把固定的隐层状态分配给分析树路径中的每一个结点(句子成分)。
本文提出了Ordered Neurons,一种能让模型的不同神经元学习不同的时间跨度的信息的诱导偏向。在其中,排序较高的神经元(在分析树中更靠近根节点一边的)偏向于学习到长期或是全局的信息;而排序较低的神经元(在分析树中更靠近叶子节点一边的)偏向于学习到短期或是局部的信息。
实现Ordered Neurons的方式就是:每当擦除或更新一个high-ranking的神经元的信息,必须同时擦除或更新一个low-ranking神经元的信息。换句话说,就是low-ranking的神经元总是要比high-ranking的神经元更新得更频繁,而这个更新的优先级(即神经元的顺序)就是作为模型结构的一部分,是预先定义好的。
具体实现(数学公式)
本论文提出了一个新的RNN单元,叫做ON-LSTM(Ordered Neurons LSTM):
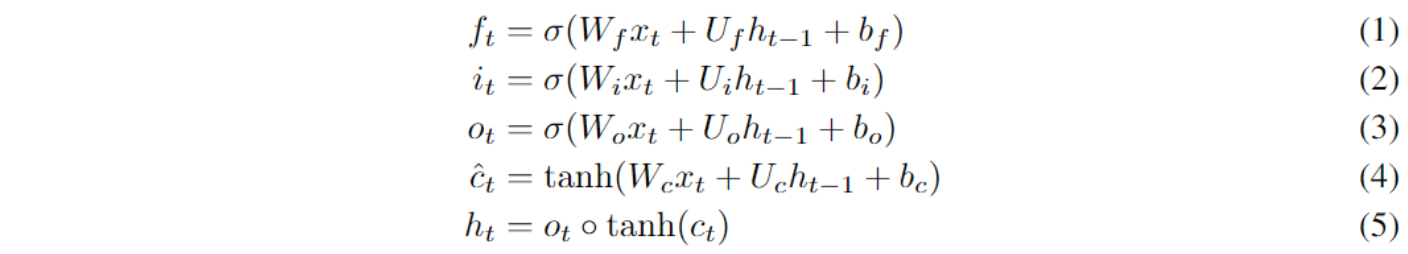
以上的部分是和常规的LSTM一模一样的。而不一样的部分就在于cell state的计算方法,传统的LSTM是:$c_t = f_t * c_{t-1} + i_t * \hat{c_t}$。其中遗忘门$f_t$和输入门$i_t$分别用来控制细胞状态$c_t$的擦除和写入。由于这些门对于每个神经元都是单独计算的,所以传统的LSTM很难去建模神经元之间的句子层级信息。
新的激活函数:cumax()
为了保证更新频率的顺序,论文提出了一种激活函数: 其中cumsum是累加求和(即对softmax的结果求前缀和)。后面将说明$\hat{g}$可以视作是二进制门$g=(0, …, 0, 1, …, 1)$的平均期望形式。这里的二进制门把细胞状态分成两段:包含0的一段和包含1的一段,由此就可以保证对神经元的擦除或更新是有序的。
引入确定的随机变量$d$来表示$g$中的第一个1的位置,那么有: 这样就能计算出$g$中的第$k$个元素是1的概率: 理想情况下,$g$应该就是一个确定的二进制门,但是由于离散随机的运算没法计算梯度,就只能在实际中采用它的期望版本,也就是softmax后的的累加和了。由于$g_k$是二进制的,因此累加softmax的前$k$项的结果就等同于$\Bbb{E}[g_k]$,因此就有$\hat{g}=\Bbb{E}[g]$。
基于cumax的细胞状态更新方法
基于cumax函数,用于控制不同句子成分的遗忘门和输入门如下:
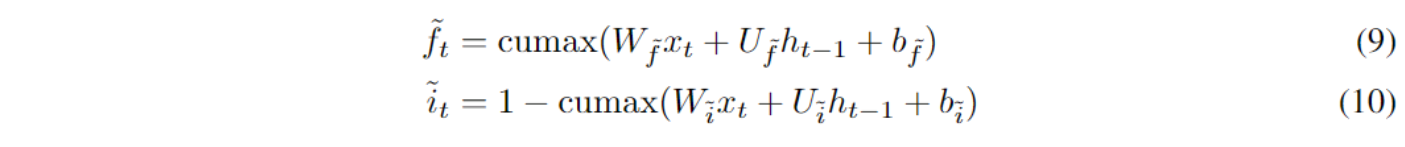
其中的遗忘门$\tilde{f_t}$是从0到1单调递增的,而输入门$\tilde{i_t}$则是从1到0单调递减的。这两者作为一个更高层次的控制门(论文中称为“master gates”),用来控制细胞状态的更新操作。
下面是基于新的控制门的细胞状态更新规则:
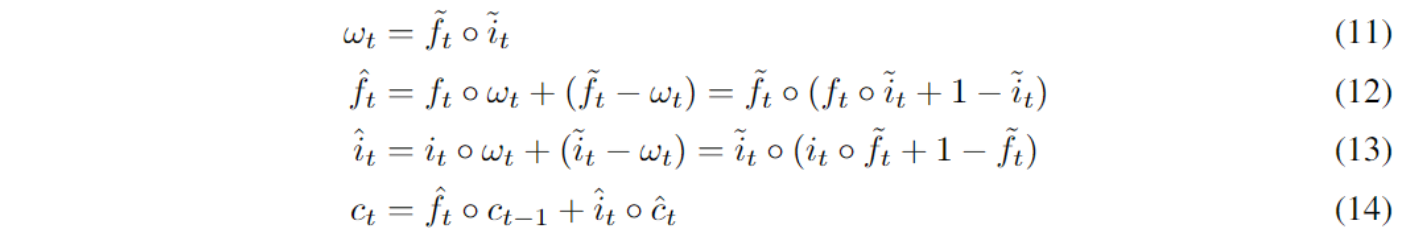
其原理说明如下:
- 假设遗忘门$\tilde{f_t}=(0, …, 0, 1, …, 1)$,其分界点为$d_t^f$,那么给定公式(12)和(14),前一个时间步的细胞状态$c_{t-1}$的前$d_t^f$个神经元会完全被擦除,这个操作的含义就相当于关闭当前的某个句子成分。一个较大的$d_t^f$就相当于关闭high-level的句子成分,反之同理,一个较小的$d_t^f$表示一个low-level的句子成分被关闭,而高层次的信息则会为之后的信息处理保留。
- 假设输入门$\tilde{i_t}=(1, …, 1, 0, …, 0)$,其分界点为$d_t^i$,那么给定公式(13)和(14),一个较大的$d_t^i$意味着当前的输入$x_t$包含了长期的信息,需要被放到high-level的神经元中保留若干个时间步;反之,一个较小的$d_t^i$意味着当前的输入$x_t$只包含了局部的信息,会在之后的时间步中很快被擦除。
- 遗忘门和输入门的乘积$w_t$代表了$\tilde{f_t}$和$\tilde{i_t}$中的重叠部分,只要这个重叠部分存在,对应的这一段神经元就会同时需要保留上一个时间步的信息并添加当前时间步输入$x_t$中的新信息,这一部分就会采用标准的LSTM更新方法进行更新(如上面图(c)中的$x_3$)。
一个汇总的表格如下:
| $\tilde{f_t}[k]$的取值 | $\tilde{i_t}[k]$的取值 | 第$k$个神经元的最终更新公式 | 备注说明 |
|---|---|---|---|
| 0 | 0 | $c_t[k] = 0 * c_{t-1}[k] + 0 * \hat{c_t}[k] = 0$ | 遗忘掉之前的信息,同时也不需要编码新信息 |
| 0 | 1 | $c_t[k] = 0 * c_{t-1}[k] + 1 * \hat{c_t}[k] = \hat{c_t}[k]$ | 遗忘掉之前的信息,编码新信息 |
| 1 | 0 | $c_t[k] = 1 * c_{t-1}[k] + 0 * \hat{c_t}[k] = c_{t-1}[k]$ | 保留之前信息,无需编码新信息 |
| 1 | 1 | $c_t[k] = f_t * c_{t-1}[k] + i_t * \hat{c_t}[k]$ | 同时需要保留之前信息和编码新信息(重叠部分) |
当然上面的解释是采用二进制门$g$的解释,但实际中会采用期望$\hat{g}$。
考虑到上述的控制门$\tilde{f_t}$和$\tilde{i_t}$是粗粒度的(控制的是句子成分中的层级结构,其深度不会很深),因此不需要细粒度的参数。所以实际中,计算$\tilde{f_t}$和$\tilde{i_t}$的参数采用的目标维度为$D_m=\frac{D}{C}$,其中$D$是隐层状态维度,$C$是一个常数。总共的$D$个神经元会被分成$\frac{D}{C}$组,每组$C$个神经元。在运算之前,会通过将$\tilde{f_t}$和$\tilde{i_t}$的每一个元素重复$C$次来获得一个$D$维的向量。
实验
作者在四个任务上进行了实验:语言模型、无监督的句子成分分析、针对性的句法评估、逻辑推理。
语言模型
在Penn TreeBank(PTB)数据集上进行实验。为了公平比较,这里采用了和另一个模型AWD-LSTM相似的超参设定、正则化和优化方法。使用的模型为三层ON-LSTM结构,隐层1150,词向量维度400。对于高层次的控制门(master gates)而言,选取的常数$C$为10,其维度为1150/10=115。对于模型的不同部分(中间的输出),分别施加了不同dropout概率(0.5, 0.3, 0.45, 0.1),模型权重有0.45的dropout概率。其结果如下图:
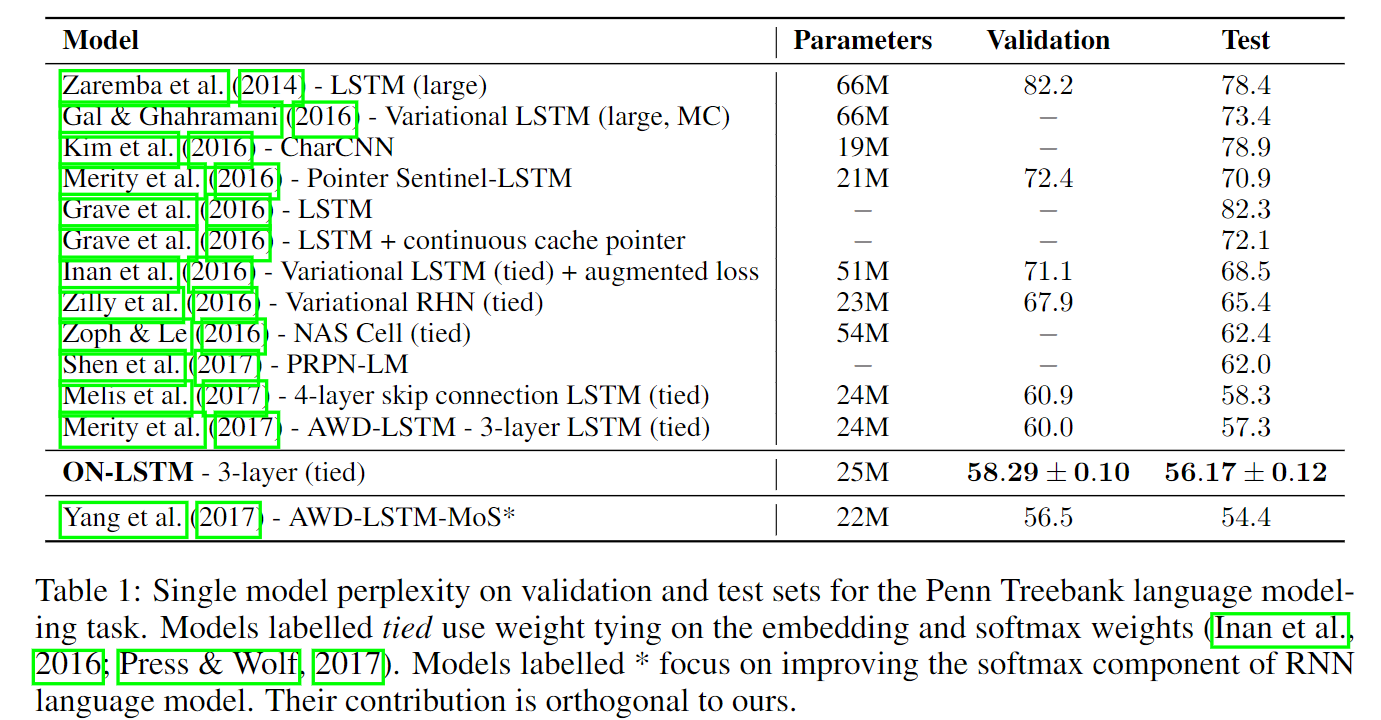 其中比ON-LSTM取得更优效果的AWD-LSTM也是研究通过改变RNN的softmax层去提升效果的工作。
其中比ON-LSTM取得更优效果的AWD-LSTM也是研究通过改变RNN的softmax层去提升效果的工作。
无监督的句子成分分析
这个任务的目标是让模型去预测给定句子的句子结构(语法树),然后和专家标注的进行比较。使用的数据集为WSJ10和WSJ测试集。WSJ10是从WSJ数据集选出来的长度(包含词语个数)小于等于10的句子,并去除了标点符号和空元素。而WSJ测试集包含不同长度的句子(没有上面的限制条件)。
这一任务就直接使用上一任务训练的(在验证集上表现最优的)语言模型来做。预测方法:每个句子的一开始都将对应的RNN隐层向量初始化为0向量,然后依次将每一个词语喂入输入层。在每一个时间步$t$,都通过如下公式估计$d_t^f$,直觉上的理解就是每个时间步关闭的句子成分相对来说位于哪个层级:
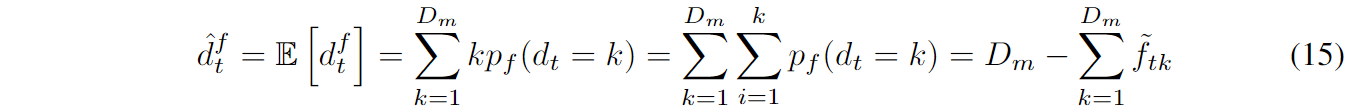 其中的$p_f$就是各个分割位置的概率分布,$D_m$为隐层向量维度。给定关闭的位置$\hat{d_i^f}$,就可以使用自上而下贪心分析算法(From一篇引文《Neural language modeling by jointly learning syntax and lexicon》)来与监督预测句子成分的结构。具体方法为:首先对${\hat{d_t^f}}$排序,然后对于排在第一位的$\hat{d_t^f}$,将句子划分为$((x_{<i}), (x_i, (x_{>i})))$,随后递归对$(x_{<i})$和$(x_{>i})$执行一样的过程,直到只剩一个词语。
其中的$p_f$就是各个分割位置的概率分布,$D_m$为隐层向量维度。给定关闭的位置$\hat{d_i^f}$,就可以使用自上而下贪心分析算法(From一篇引文《Neural language modeling by jointly learning syntax and lexicon》)来与监督预测句子成分的结构。具体方法为:首先对${\hat{d_t^f}}$排序,然后对于排在第一位的$\hat{d_t^f}$,将句子划分为$((x_{<i}), (x_i, (x_{>i})))$,随后递归对$(x_{<i})$和$(x_{>i})$执行一样的过程,直到只剩一个词语。
实验结果如下图:
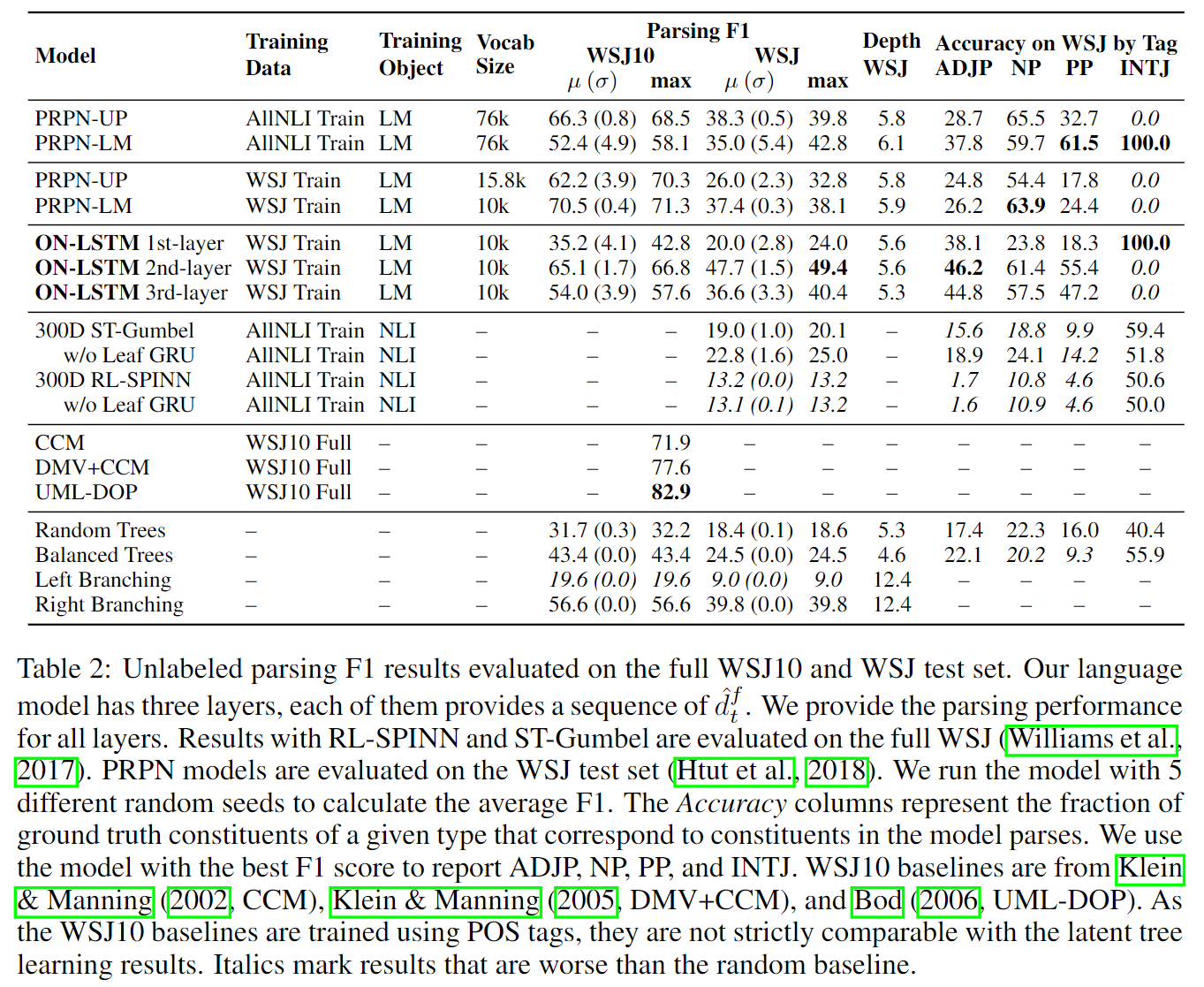 可以看到语言模型的第二层在WSJ测试集上获得了最优的效果,而第一层和第三层则不如第二层效果好。作者的推断是第一层和第三层分别与输入层和输出层相连,因此可能需要更加注重捕获、处理语言模型相关的本地信息,因此可能相对忽视了学习更加抽象的树形句子结构(有review指出这里的解释有点牵强,示意作者去做实验,例如在只包含两层的语言模型上的表现会怎样等)。
可以看到语言模型的第二层在WSJ测试集上获得了最优的效果,而第一层和第三层则不如第二层效果好。作者的推断是第一层和第三层分别与输入层和输出层相连,因此可能需要更加注重捕获、处理语言模型相关的本地信息,因此可能相对忽视了学习更加抽象的树形句子结构(有review指出这里的解释有点牵强,示意作者去做实验,例如在只包含两层的语言模型上的表现会怎样等)。
下图(包含在原文的附录中)给出了更多的基于ON-LSTM训练的语言模型的第二层导出的句子成分结构推断图(左),并与标注的ground truth(右)进行了比较。

针对性的句法评估(Targeted Syntactic Evaluation)
这一任务是在2018年的一篇论文中提出的一组数据集,用于评估语言模型在三种不同的对句法结构敏感的情形下的表现。这三种情形分别是:主谓一致(subject-verb agreement)、反射回指(reflexive anaphora,后文的代词映射到前文中的实体)、否定项(negative polarity items)。
这个数据集包含在上述情形下的各种positive-negative pairs,positive指符合语法的,negative指不符合语法的,用来测试语言模型对此的辨别度(期望语言模型对符合语法的句子给出较高的概率)。实验结果如下图:
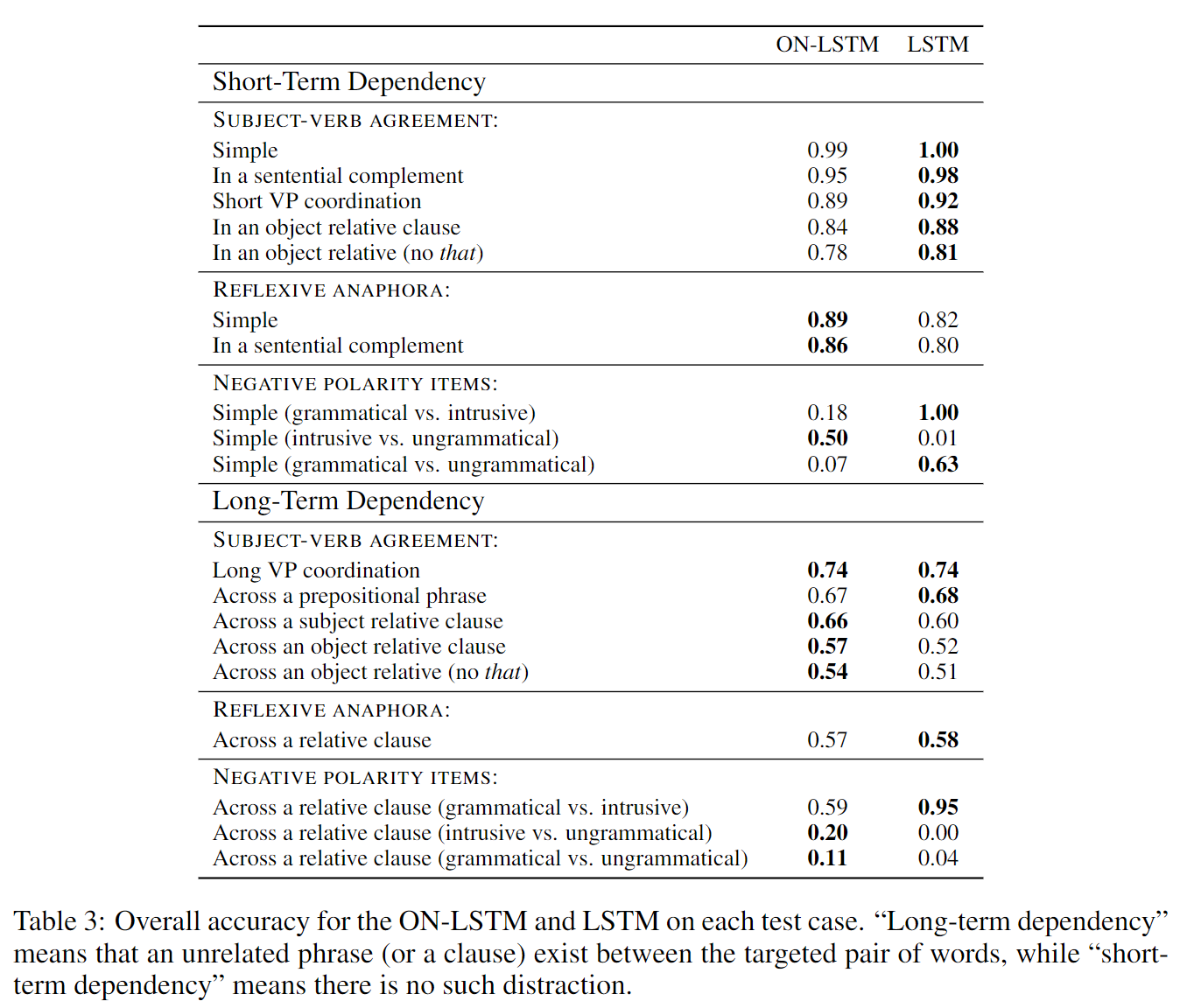 总体上标准LSTM在short-term的任务上有好一些的表现,而ON-LSTM在long-term任务上表现更好一些。
总体上标准LSTM在short-term的任务上有好一些的表现,而ON-LSTM在long-term任务上表现更好一些。
逻辑推理
这一任务中的句子包含6个词语(即命题p1, p2, …, p6)和三个逻辑关系:与或非。例如一个句子可能是:“(p1 or (not p2)) and (p3 or (not p4))”。任务要求判定两个给定句子的逻辑关系(等价、蕴含、独立等,共7种可能的关系)。
作者在标准LSTM和ON-LSTM上分别进行了试验。模型结构为:两个句子经过一个RNN编码器,获取其最后的隐层向量$(h_1, h_2)$作为句子编码。然后将$(h_1, h_2, h_1 * h_2, abs(h_1 - h_2))$的拼接作为特征输入一个前馈神经网络分类器,包含7个类别。实验中RNN包含400个单元,单层,输入维度128。两个模型都在长度少于6的句子上进行训练,然后在最多包含长度12句子的测试集上进行测试,结果如下图:
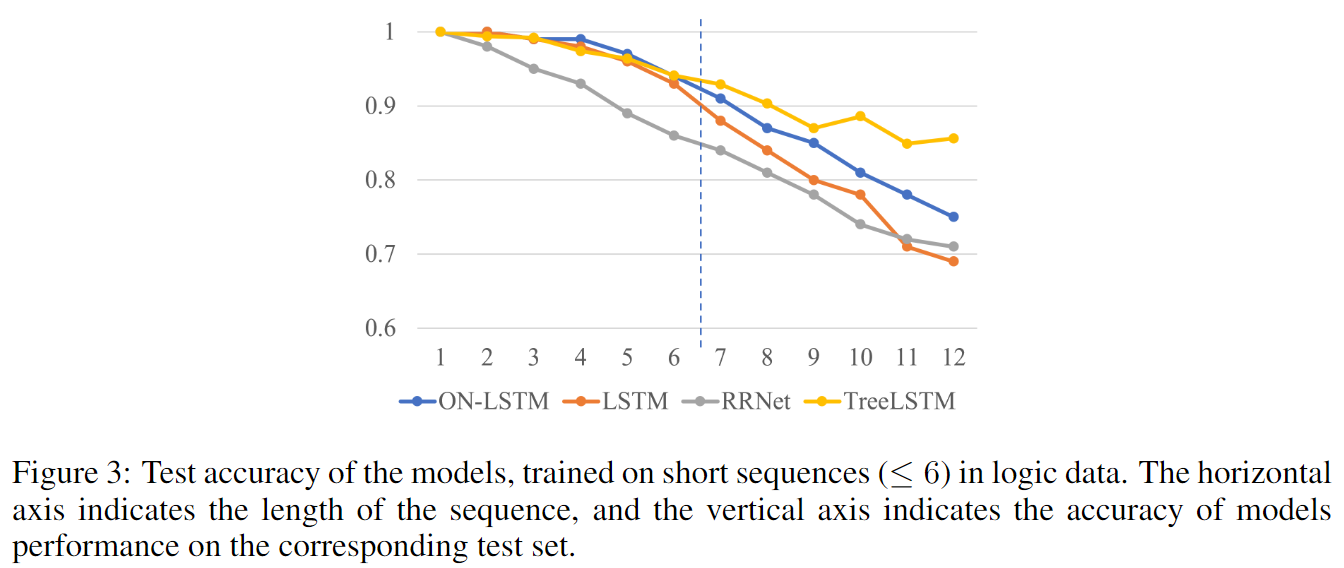 其中Tree-LSTM能在此数据集上获取更好的性能,是因为它提供了句子的树形结构(ground truth)作为输入。
其中Tree-LSTM能在此数据集上获取更好的性能,是因为它提供了句子的树形结构(ground truth)作为输入。