《Locale-agnostic Universal Domain Classification Model in Spoken Language Understanding》阅读笔记
Conference from: NAACL2019
Paper link: https://arxiv.org/pdf/1905.00924
本文要解决的问题
目前有很多智能私人数字助手(Intelligent Personal Digital Assistants, IPDA)像是Amazon Alexa、Google Assistant、Apple Siri、Microsoft Cortana等。它们的成功使得这些产品在不同地域(Locale)发行,例如美国(US)、英国(UK)、加拿大(CA)、印度(IN)等。典型的做法是对每一个地域(Locale)都定制一个该地域专属(本地化)的领域分类模型(Domain Classification Model)。这样就产生了两个问题:
- 为每个地域构建单独的分类模型会导致所需的资源和维护成本随地域数量增加也线性增加
- 新的地域往往没有很多的训练数据,为每个地域单独构建模型会导致原有的其它地域的数据没有被充分利用
本文就为了解决上述跨地域(Locale)的SLU领域分类(Domain Classification)问题。形式化的定义为:假设有$k$个地域:${l_i|i=1,2,…,k}$,每个地域$l_i$有专属与这个地域的domain集合:$D_i={d_{ij}|j=1,2,…,|D_i|}$。这些跨地域domain中可能有公共的部分。这些跨地域公共domain中可能有些有完全相同的intents/slots,有些则根据其地域有不同的intents/slots。本文要解决的问题就是:给定一个来自地域$l_i$的输入句子,模型需要将这句话正确分类到一个domain $d_{ij} \in D_i$中。本文假设了这些不同的地域都使用同一种语言——英语。
动机&启发
这一章叙述了下一章设计模型的一些考虑。
地域/领域-成熟度(Maturity)
作者将成熟度(maturity)定义为一项服务或模型在一个地域部署的时间长短,以及其收集的数据多少。作者认为不同地域具有不同的成熟度,也就是说有些地域花了足够长的时间,收集了足够多的数据来训练模型;而其它一些地域则没有那么多的数据。
作为补充,相同领域也会根据地域的差异而具有不同的成熟度。并且地域和领域这两个维度的成熟度不一定是对齐的,而可能是交叉的,就是说可能存在:成熟度低的地域的某个领域比成熟度高的地域的这个领域具有更高的成熟度。
地域-特异性(Specificity)
当SLU服务被部署到不同的地域时,每个地域都有其特定的领域集合(Domain Set)。这些领域集合之间可能相互存在重叠(共享)的情况。在这些共享的领域中,有些领域可能是共享完全相同的intents/slots,这种情况下就可以无视地域差异,学习到共享的知识,从而帮助成熟度低的地域克服缺少数据的问题。
但是特殊的,可能存在地域特定(locale-specific)的共享领域。也就是说,尽管该domain在多个地域中都有出现,但是其模式根据不同的地域而有所差异。一个例子为OpenTable领域,这个领域被同时包括在美国(US)和英国(GB),但当用户说“Make a reservation for The Fox Club London”时,它只能被英国的OpenTable处理,因为The Fox Club London这家餐馆位于英国。因此作者认为,如果让具有地域差异的领域共享知识,可能会导致模型将这些差异混淆。
因此需要让存在地域差异的公共领域对不同的地域有所区分。同样,需要对专属与某个地域的私有领域也进行类似的区分。
模型
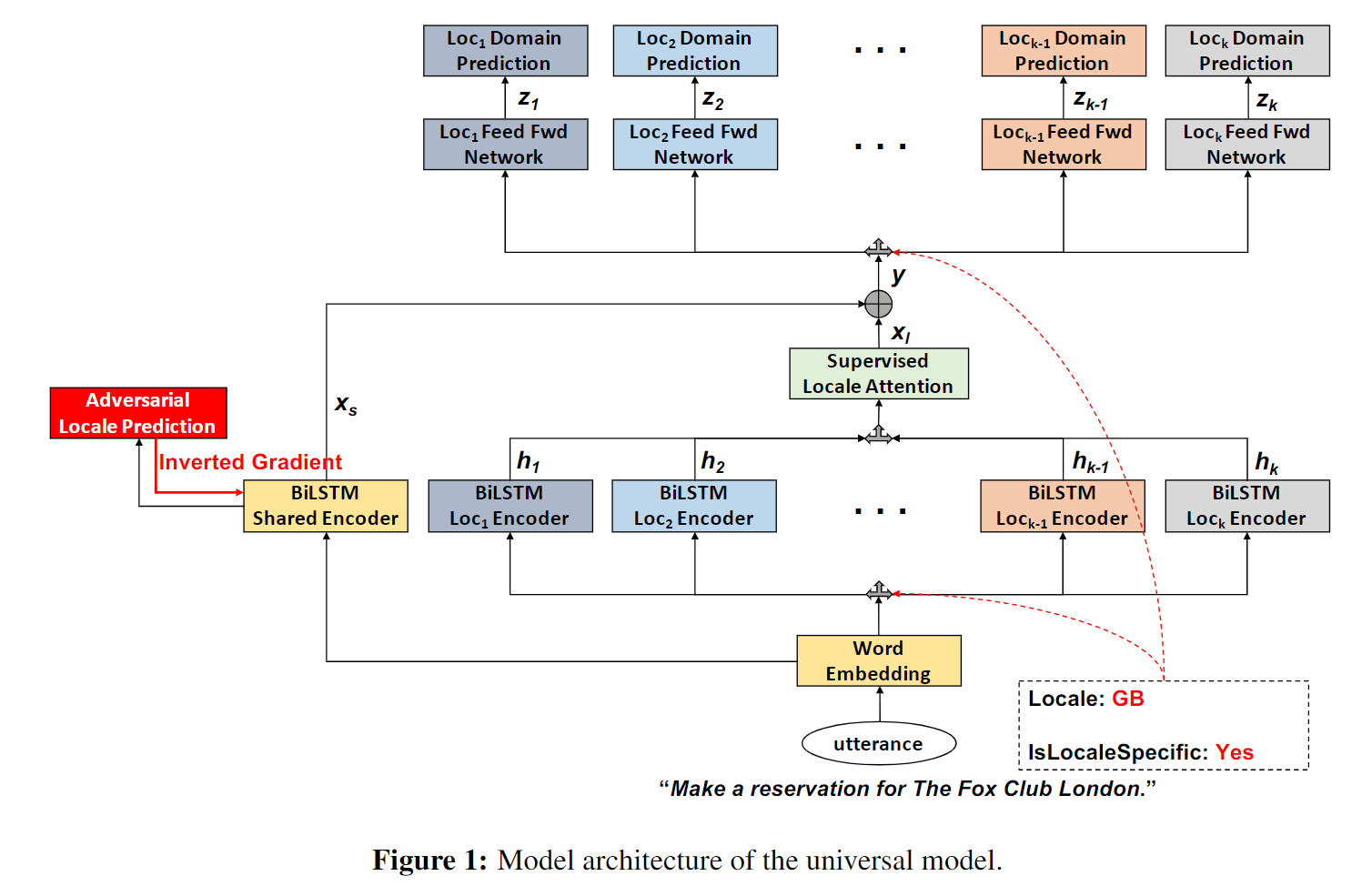
共享和地域特定的编码器
本文采用了多任务联合训练模型,使用一个共享编码器编码地域公共的特征,$k$个locale-specific编码器编码地域私有的特征。每个编码器都采用双向LSTM实现,并将最后时间步的隐层状态拼接作为输出。
对抗损失
为了保证共享编码器学习到公共的、领域无关的特征,使用了一个单层神经网络: 其中$\bf{W}{adv}$和$\bf{b}{adv}$是可训练的参数,$x_s$为共享编码器输出。为了让共享编码器地域不可知,使用了正对数似然损失(猜得越准惩罚越大): 其中$t_i$是0或1,表示$l_i$是否是一个正确的预测。
有监督的跨地域Attention
这一模块的设置是为了让跨地域的领域知识得以共享。考虑所有领域$d_{ij}$,用一个集合$S_{d_{ij}}$来表示该领域所出现的所有地域集合,即$S_{d_{ij}}={l_w|d_{ij} \in D_w, \forall w=1,2,…,k}$。特殊地,当$d_{ij}$为该地域特有时(包括前面的OpenTable的例子),$S_{d_{ij}}={l_i}$。因此理想情况下,为了共享知识,就需要考虑这个集合中所有地域特定的编码器的输出。但是在预测时并不能获知这样的ground truth,来表示和哪些其它地域的知识相关联。
因此作者提出了有监督的Attention的方式,来近似获取哪些地域的知识可以共享的信息。
具体运算如下:让 $\bf{H}=[\bf{h}{l_1}, \bf{h}{l_2}, …, \bf{h}{l_k}] \in \mathbb{R}^{d_h \times k}$ 表示locale-specific编码器输出向量构成的矩阵,随后,attention权重计算如下: 其中 $\bf{w} \in \mathbb{R}^{d_a}$ 和 $\bf{V} \in \mathbb{R}^{d_a \times d_h}$ 是可训练参数,$d_a$是一个可以任意设定的超参数。随后,locale-aware的向量根据attention权重对$\bf{h}{l_1}, …, \bf{h}_{l_k}$计算线性组合后得到: 最终的向量表示为 $\bf{y} \in \mathbb{R}^{2 \times d_h}$,是共享层的输出向量$x_s$和$x_l$拼接后的结果。
但注意这里需要让集合$S_{d_{ij}}$内的地域获得较高的Attention权重,因此可以采用有监督的方式对权重$\bf{V}$和$\bf{w}$进行另一个目标的训练。在训练时,可以获知一个输入句子的真实领域(ground truth),因此就可以知道哪些地域包含了这个相同的领域(即$S_{d_{ij}}$),从而可以根据这个对attention权重进行一个奖励或惩罚,定义如下:
领域分类
模型为每一个地域$l_i$设置了一个专属的分类层: 其中$\bf{W}_i$和$\bf{b}_i$是对应到地域$l_i$的可训练参数。$\sigma$是激活函数。
由于本文的模型是多任务联合训练模型,以获取跨地域的表示,因此模型会对所有的$l_i \in S_{d_{ij}}$计算$\bf{z}_i$,然后通过下列公式计算损失:
最后的目标函数如下: 其中$\theta_{\mathcal{F}s}$和$\theta{\mathcal{F}_l}$分别是共享和地域专属编码器的参数。
实验
数据集
实验中使用的数据集为Amazon Alexa收集的数据集的一个子集,来自不同地域:US、GB、CA、IN,但语言都是英语。每一个句子都被标注了ground-truth的domain信息。实验的目标是展现不同模型对这多个地域不同的domain集合和不平衡的数据样本的适应性。为此,作者将所有domains分成了四类:
- Locale-specific: 该领域在该地域中具有特殊的的intents/slots
- Locale-independent: 该领域在多个地域中共享相同的intents/slots
- Single-locale: 该领域只在这个地域中出现
- Small: 该领域在某地域中缺少数据,但是在其它地域中有充足的数据
数据集综合统计如下表:
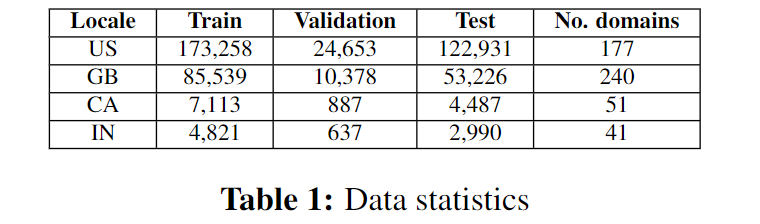
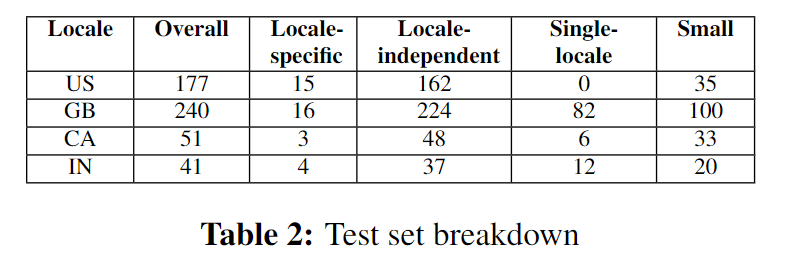
各个地域的domains分类如下表:
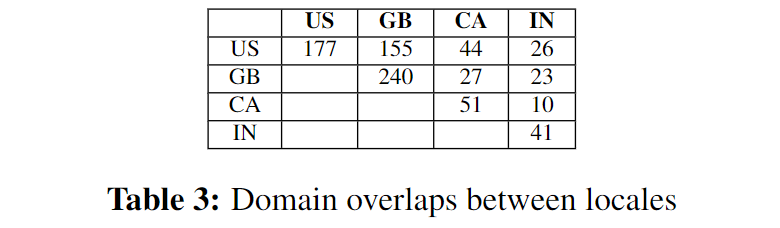
不同地域的domains重叠情况如下表:
比较模型
- single: 标准的基于BiLSTM的编码器,只在特定的某个locale的数据下训练
- union: single的方法,额外加入US的数据
- constrained: 在所有的地域数据训练,通过地域信息使得输出空间限于domains的一个子集 (Kim et al., 2016b,a)
- universal: 本文提出的模型(不加对抗损失)
- universal + adv: universal的模型,加上对抗损失
结果
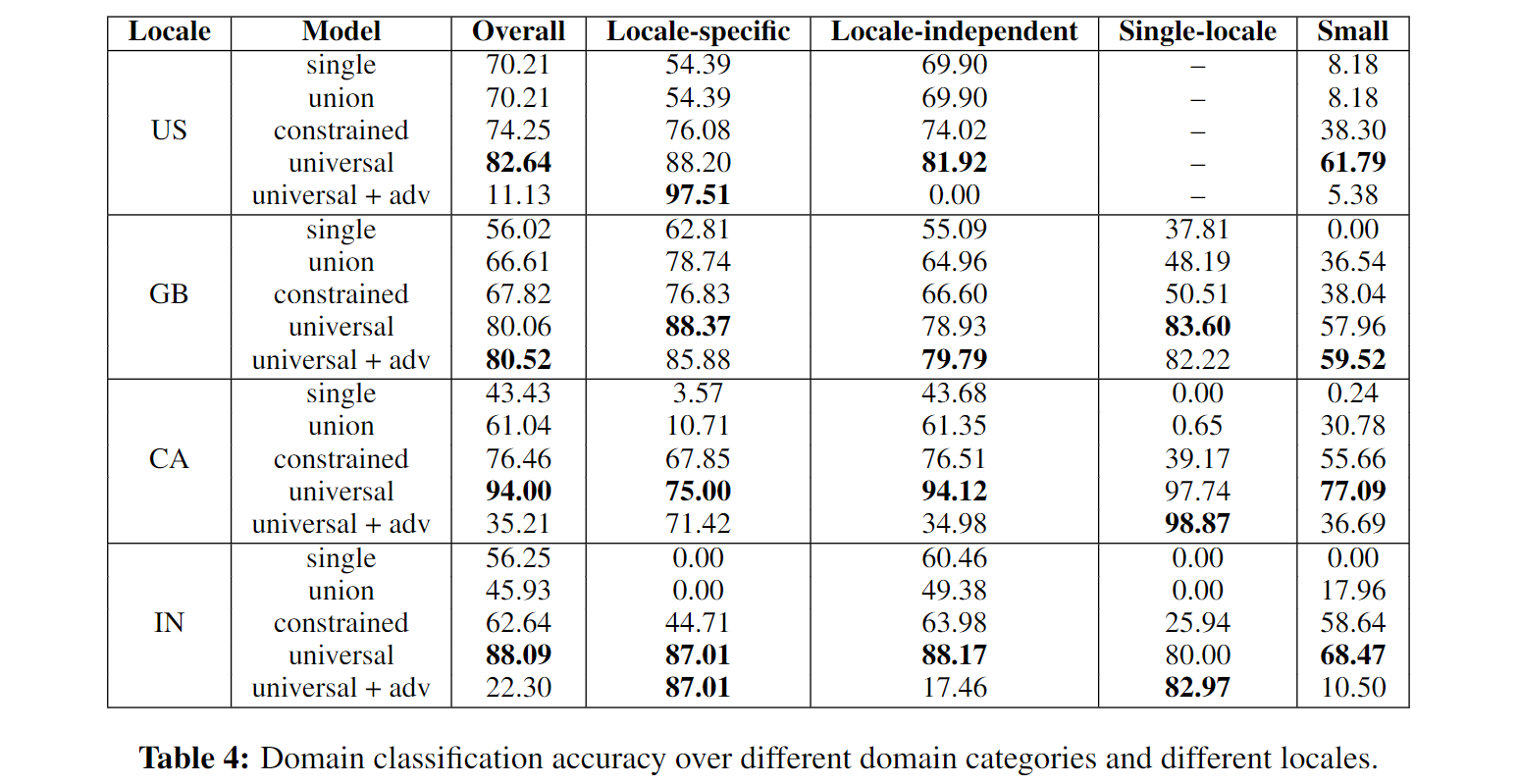
作者指出的几个要点:
- 本文提出的模型在所有地域和不同的领域分类集合都比baseline模型效果要好
- baseline模型效果很差,尤其是在使用其它地域的数据显得非常重要的领域(例如small);或是需要根据地域特异性选择性的共享知识的领域
- 如果一个模型允许共享跨地域的知识,但是没有很好地处理地域特异的模式,其性能就会下降,例如“constrained”模型使用了一个公共编码器,并且允许不同地域共享输出层,但它没有对不同领域是否共享知识做一个处理,其在IN地域的结果,对于Locale-specific和Single-locale的情况就比较低
- 同样,“single”和“union”模型没有机会学到共享知识的表示,因此在locale-specific、single-locale和small类别的domains中都表现不太好
- 对抗损失只对于locale-specific和single-locale类别的领域分类有用,作者认为对抗损失会使得模型只依赖于locale-specific的编码器。但对于为什么没有影响GB地域,作者认为需要进一步深入分析,“and we leave if as future works”
:That is probably because the effect of adversarial loss paradoxically makes the model rely on only the locale-specific encoders which are well-optimized for locale-specific/single-locale domains