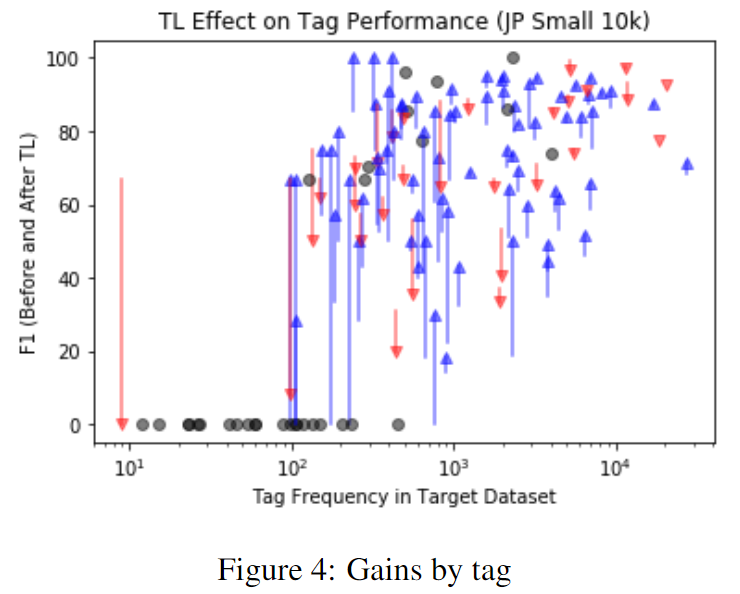
《Cross-lingual Transfer Learning for Japanese Named Entity Recognition》阅读笔记
Conference from: NAACL2019
Introduction
本文要解决的是NER任务的跨语言迁移问题。本文的特点在于:
- 研究的迁移方法为模型权重迁移
- 专注于差异相对较大的两种语言之间的迁移
本文认为传统的NER迁移的任务都做的是比较类似的两种语言之间的迁移,例如从英语迁移到德语或西班牙语;而本文专注于差别较大的语言之间的迁移,即英语到日语。
本文的贡献如下:
- 提出了将日文罗马音化的方法,从而将日语转换成拉丁字符集,使得能和英语共享字符级别的embedding特征
- 探索了权重迁移的不同组合对最终性能的影响
- 实验结果显示本文的迁移方法在公开数据集和内部数据集上都相比baseline(不进行迁移)获得了性能提升;进一步的实验还探索了数据集大小、tag分布对提升性能大小的影响
NER model
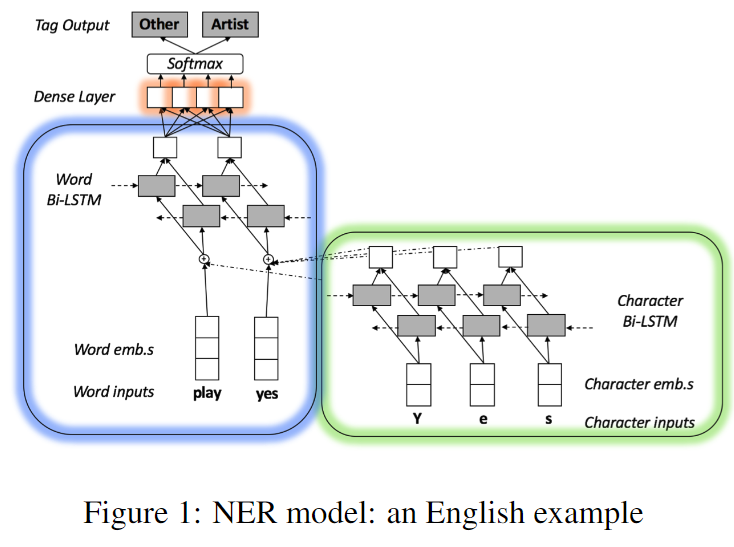
本文使用的baseline模型如上图。这里的三个框分别代表了字符级别编码、单词级别编码、输出这三个模块。需要注意的是其中字符级别的输入实际中采用bigram的方式(而不是图中的single character),例如对于“Yes”会使用“Ye”和“es”。
Transfer Learning
Related work
这里作者引用前人的论文,要点包括:
- Lee et al. (2017) 探索了从低层到高层迁移权重对迁移效果(TL gains)的影响
- Yang et al. (2017) 建议只迁移字符级别的权重(上图的绿色方框部分),原因是该文章作者认为很多用拉丁字母书写的语言都在字符级别有很大程度的重叠,但在词语级别这种重叠则会少很多
- 很多工作都显示,语言的相关性对NER、POS tagging、NMT等任务的迁移会有帮助。在Yang et al. (2017)中,其作者认为“Without additional resources, it is very difficult for transfer learning between languages with disparate alphabets”,所以本文作者认为研究从英语到日语迁移学习是特别的、有意义的
Specificities of Japanese language
这里作者指出了日语的语言特点,它是不进行分段的、由两种假名和成千上万的汉字构成。
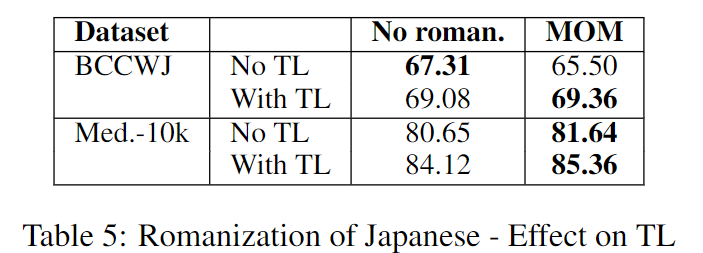
作者使用了罗马音化(romanization)的方法,将日文转换成拉丁字母的书写形式(类似于使用拼音来表示中文)。但这么做会导致同音词的问题,如下:

这些同音词在使用日文书写时,并不会有歧义,但是将其转化成罗马音之后,其日文字符的信息就被丢失了,因此就会导致歧义。此前的工作 (Zhang and LeCun, 2017) 也显示了将日文转化成罗马音会降低单语言模型的性能。
Proposed model
由于本文探索的是权重迁移,其中一个重要的问题就是怎样的迁移权重组合能让迁移获得的提升最大。为了研究这个问题,本文将模型权重分成了三组(如之前的章节所述),并对不同的迁移组合在实验中进行了探究。
同时为了克服上述的同音词歧义的问题,也为了同时解决不同书写系统的迁移问题,本文提出了称为 Mixed Orthographic Model (MOM) 的模型。具体来说,就是在character embedding层使用罗马音形式,而在word embedding层保留原先的日文形式作为输入,如下图所示:

值得注意的是,本文在迁移过程中,只对英语和日语中共有的words和char n-grams进行embeddings的迁移。其提到了可以使用多语言的embeddings作为future work。
Experimental setup
这里作者介绍了其使用的数据集,包括内部数据集和外部(公开)数据集。以及一些超参数设定等。
Results
Layer combinations for TL
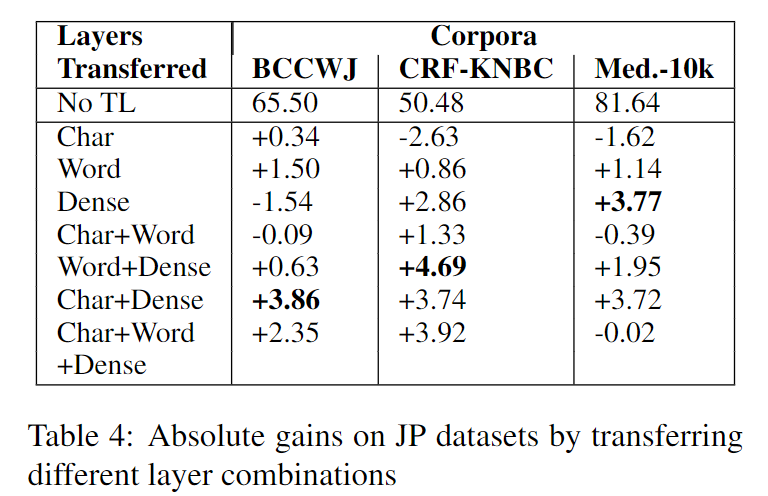
其中的几个要点:
- 最优的迁移组合随数据集的不同而不同,但看起来“Char+Dense”的组合对三个数据集都有不错的性能提升
- 和 (Yang et al., 2017) 的结论(只迁移字符级别)不同,实验中发现只迁移“Word”的性能好过“Char”,作者预计是因为本文专注于两种不相似的语言的迁移
- “Word+Dense”和“Char+Dense”相比只迁移“Word”和“Char”,均有性能提升,说明Dense层确实能捕获到一些语言无关的公共信息(知识)
Effect of romanization of Japanese on TL
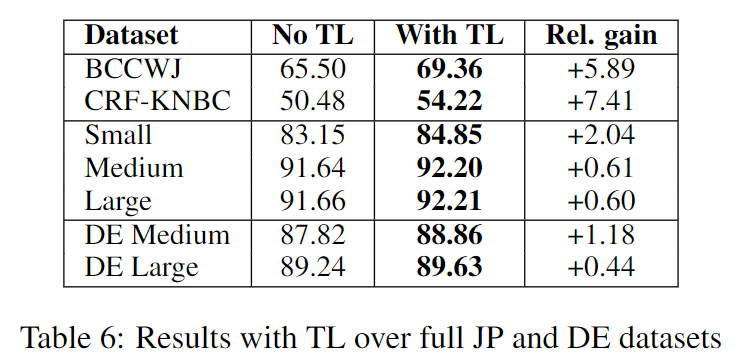
TL on external and internal datasets
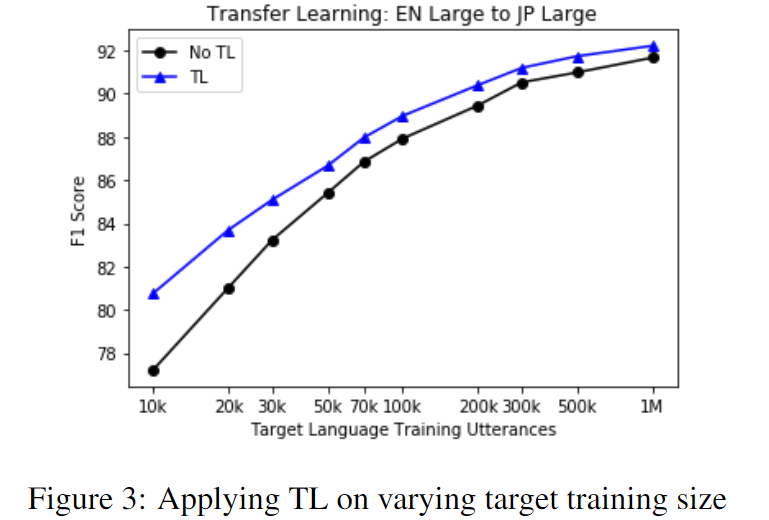
Effect of target dataset size on TL