《(Almost) Zero-Shot Cross-Lingual Spoken Language Understanding》阅读笔记
Conference from: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2018)
Paper link: http://shyamupa.com/papers/UFTHH18.pdf
本论文拟解决的问题
SLU(Spoken Language Understanding)任务指的是分析、理解用户的自然语言输入,将其转化为机器能够理解的形式(包括意图识别和槽填充)。
本文旨在解决跨语言的SLU任务迁移。目前SOTA的SLU模型在英语领域已经获得了很高的性能,但是于其他语言,因为种种原因(数据不足等),仍然无法取得较高性能。
目前将英语SLU迁移到其他语言领域的方法主要是采用机器翻译技术,但是机器翻译对于一些低资源(low resource)的语言本身就不太可靠,因此本文主要想通过低成本、少标注的方法,解决SLU从英语迁移到其它低资源语言的问题。

相关工作
之前的将SLU从英语迁移到其它语言的方法大多采用机器翻译,这里有两种方法:
- Test On Source
- Train On Target
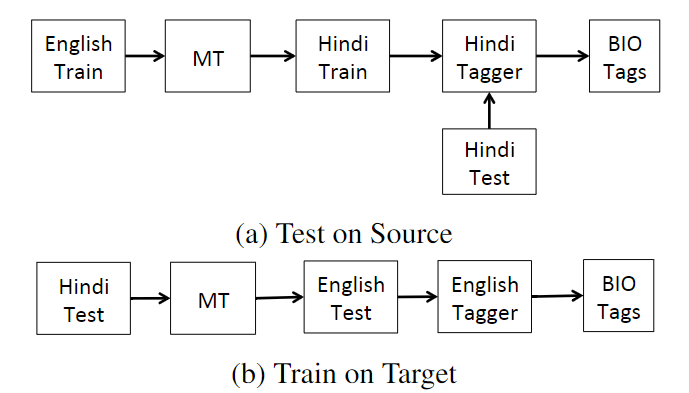
前者(Test On Source)指的是在测试时,将目标语言翻译成英语,然后使用英语SLU模型完成SLU任务。后者(Train on Target)指的是在训练时将英语训练语料通过机器翻译,翻译成目标语言的训练语料,在此基础上训练一个目标语言的SLU模型。
这两种方法的缺点:
- 都依赖于机器翻译,但是机器翻译在一些低资源语言上本身就是不可靠甚至无法训练的。此前的这一类工作的目标语言大多数都是流行的语言,例如汉语、法语、西班牙语等,英语-目标语言的翻译质量比较好。
- 在第一个方法(Test On Source)中,因为需要先把预测的文本翻译成英语,增加了额外的reference延迟
- 机器翻译训练的语料和SLU训练的语料不同(前者是任意的平行语料;后者是对话中的平行语料),两者具有领域差异,可能会带来不好的效果
此外还提出了上述两个方法的一些变体,其中一个就是基于Test On Source方法的变体,它在训练英语SLU的时候不单单采用英语语料。而是将英语翻译成目标语言,再把目标语言反向翻译回英语,将通过这种方法得到的训练样本和原始的样本混合,在此基础上去训练英语SLU模型。其背后的启发就是:通过这种方法能够让SLU模型能够自适应处理机器翻译过程中带来的干扰,从而在做reference的时候能够避免翻译不准确带来的SLU识别错误。
句子对齐的方法
无论是Test On Source还是Train On Target的方法,都需要将翻译后的句子和原句子对齐,从而将原句中的slot信息tag到翻译后的句子上。这篇文章没有具体对这个过程说明,但在它的两篇引文中能够找到方法。
一篇文章是《Multi-Style Adaptive Training for Robust Cross-Lingual Spoken Language Understanding》,它提出的就是Test On Source的变体(A->B->A翻译训练数据,增强模型对翻译中引入噪声的鲁棒性)。在这篇论文中,能找到下面这段话
 为了将经过A->B->A翻译过程后的训练文本附上原先的标记,它使用了在一篇引文[9]中能获取到的单语言(monolingual)句子对齐的方法。这篇引文为:《Indirect HMM Machine Translation Systems》,发表在EMNLP 2008。
为了将经过A->B->A翻译过程后的训练文本附上原先的标记,它使用了在一篇引文[9]中能获取到的单语言(monolingual)句子对齐的方法。这篇引文为:《Indirect HMM Machine Translation Systems》,发表在EMNLP 2008。
不过在上面一篇文章中并没有找到描述如何在reference的时候做双语言对齐的方法(需要把翻译后的句子的slot信息映射回翻译前的句子)。
另外一篇文章是《Investigating multiple approaches for SLU portability to a new language》,这是本论文关于Train On Target方法的引文的引文,它描述了做SLU迁移的几种方法。在这篇文章中,它详细(用了一个小节)描述了做对齐的两种方法:
- 最简单地,将每种tag的部分分别翻译,如下图:

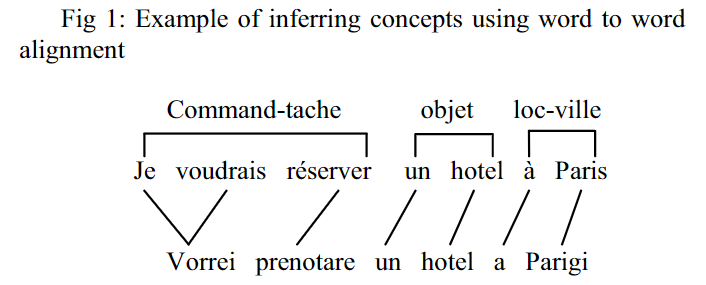
- 使用Word-to-Word Alignments:即使用现成的一些做无监督语言对齐的工具包,例如GIZA++,它使用了IBM和HMM模型;以及Berkeley aligner,使用了alignment by agreement model。这篇文章就是使用的Berkeley aligner。示意图如下:
在上面的第二种方法中,还会有一个问题,就是:在对齐的过程中,可能出现两个本属于不同的slot的word合并成了一个词,如下图:
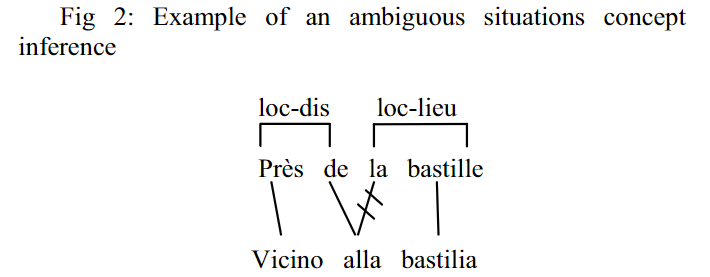 这个时候这篇文章将简单地将其分给前一个部分的slot。
这个时候这篇文章将简单地将其分给前一个部分的slot。
本论文提出的方法
本文提出了一种能够将SLU模型从英语迁移到目标语言的方法,而无需依赖机器翻译系统。
基础模型
本文首先提出了SLU任务的基础模型,主要受到联合训练slot filling和intent classification模型的启发:
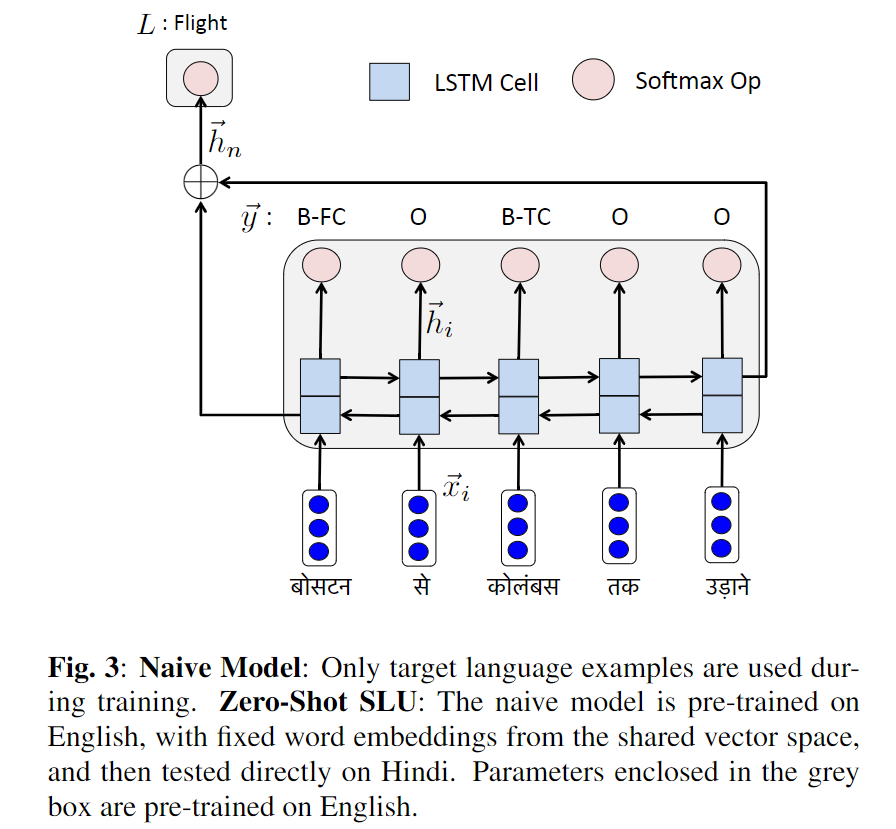
基础模型就是简单地将word embedding后的向量序列经过一个双向LSTM,每一个时间步的隐层输出$h_i$经过softmax后就是对应的slot filling的序列;LSTM最终的状态$h_n$经过softmax后就是对应的intent。
aligned word embedding
上面的基础模型能够在英语或目标语言上进行训练。为了利用能够轻易获取到的英语语料预训练来提高目标语言的性能(迁移学习),本文使用了aligned word embedding的方法。
这一技术的意思是,为了能在两种语言的语料上共享SLU模型参数,需要在词语表示的这一层(即word embedding层)就将两种语言的相同含义的词语在向量空间中的向量表示进行对齐。例如:英语“cloud”和中文的“云”,需要将两者映射到向量空间中相接近的地方(i.e. 两者的余弦相似度需要接近于1)。
Aligning word embedding此前也有了一些研究(见原文的引用),一种方法是使用两个线性变换矩阵$\bf{W}$和$\bf{V}$,分别对两个语言的word embedding矩阵做线性映射,映射到相同维度的向量空间中,要求在映射后的向量,两种语言中语义相同的词语具有相似的向量表示(两者的余弦相似度较高)。
本论文使用的word embedding模型来自论文《Enriching word vectors with subword information》,其github上的项目提供了157种语言在维基百科上的预训练模型。在这些word embedding模型的基础上,基于论文《Offline bilingual word vectors, orthogonal transformations and the inverted softmax》(ICLR 2017)的方法将其转化为双语言的aligned word embeddings。作者说也尝试了其它aligning embeddings的方法如CCA(论文《Improving vector space word representations using multilingual correlation》),但是没有现成模型的效果好。
采用了aligned word embedding(publicly available)之后,原来的基础模型就能够先在英语语料上进行训练,然后Zero-Shot地迁移到目标语言上进行测试了。如果还有目标语言的少数语料,还可以接着在目标语言的语料上进行训练。在训练的过程中,为了保证预训练的aligned word embedding的双语言对齐特性,这些参数是不进行更新的。
双语言共同训练
另外一种方式是可以通过aligned word embedding,将双语言(英语和目标语言)语料随机混合,共同参与训练,也就是不再分前后的顺序了。模型如下:
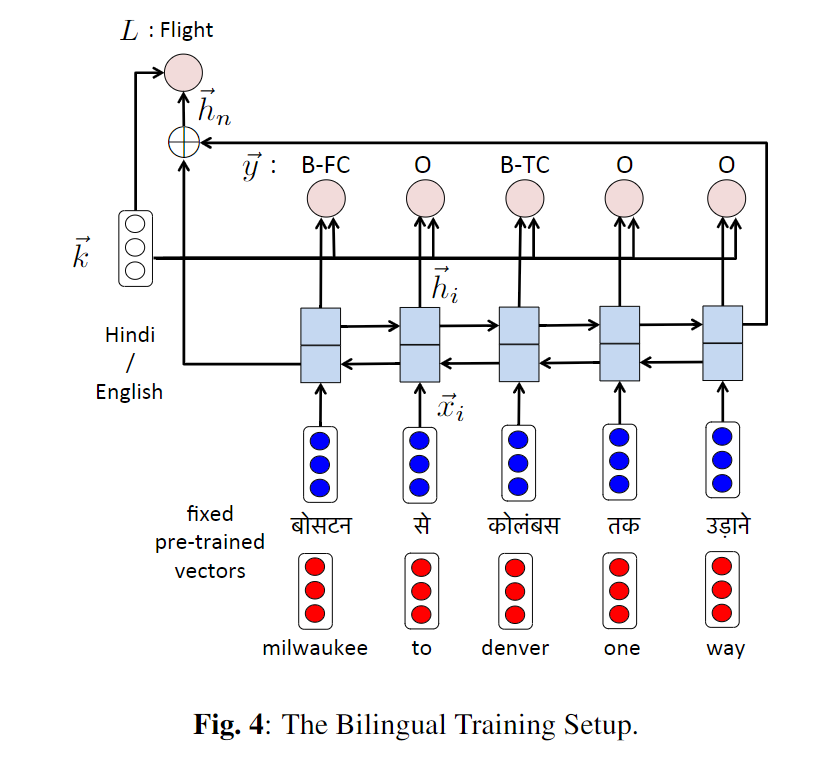
相较于基础模型,这里额外添加了一个向量$\overrightarrow{k}$用来区分当前的训练文本属于哪一个语言(英语OR目标语言)。它将会与基础模型softmax层的输入拼接后再通过softmax层。
实验
数据来源
实验在两种相对低资源的语种上进行了训练:印地语(Hindi)和土耳其语(Turkish),其数据来源于对ATIS数据集的翻译工作。目标语言的训练集即随机翻译ATIS的部分训练集样本;目标语言的测试集即随机翻译ATIS的测试集样本。在对比试验(即传统的基于机器翻译的迁移)使用的翻译系统为谷歌翻译。
实验结果
Slot-filling的F1结果如下图:
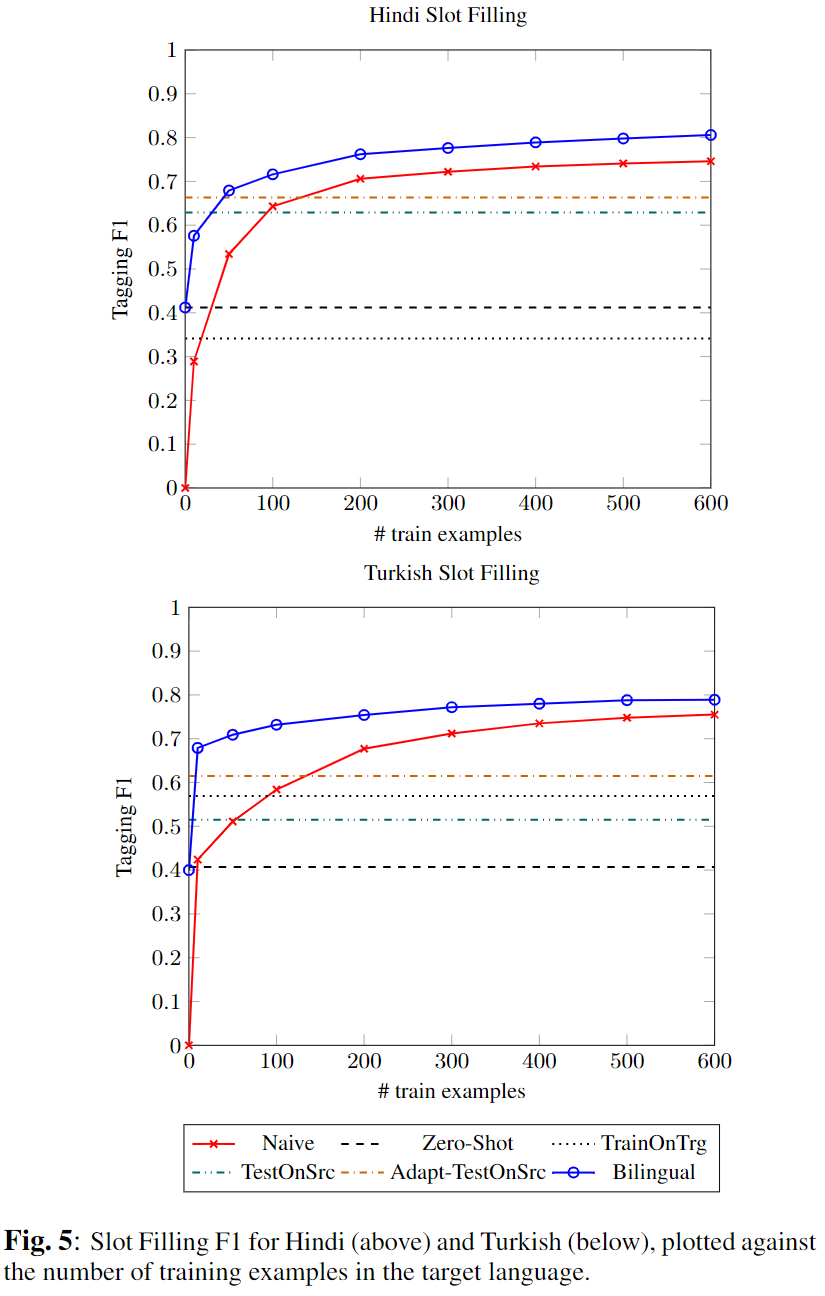 这里采用了上面所说的三种迁移方法作为比较,分别是Train On Target(TrainOnTrg)、Test On Source(TestOnSrc)、以及上面提到过的Test On Source的一个变体(Adapt-TestOnSrc),它们均在ATIS的全训练集上(约5k样本)进行训练。
这里采用了上面所说的三种迁移方法作为比较,分别是Train On Target(TrainOnTrg)、Test On Source(TestOnSrc)、以及上面提到过的Test On Source的一个变体(Adapt-TestOnSrc),它们均在ATIS的全训练集上(约5k样本)进行训练。
Intent-classification的准确率如下:
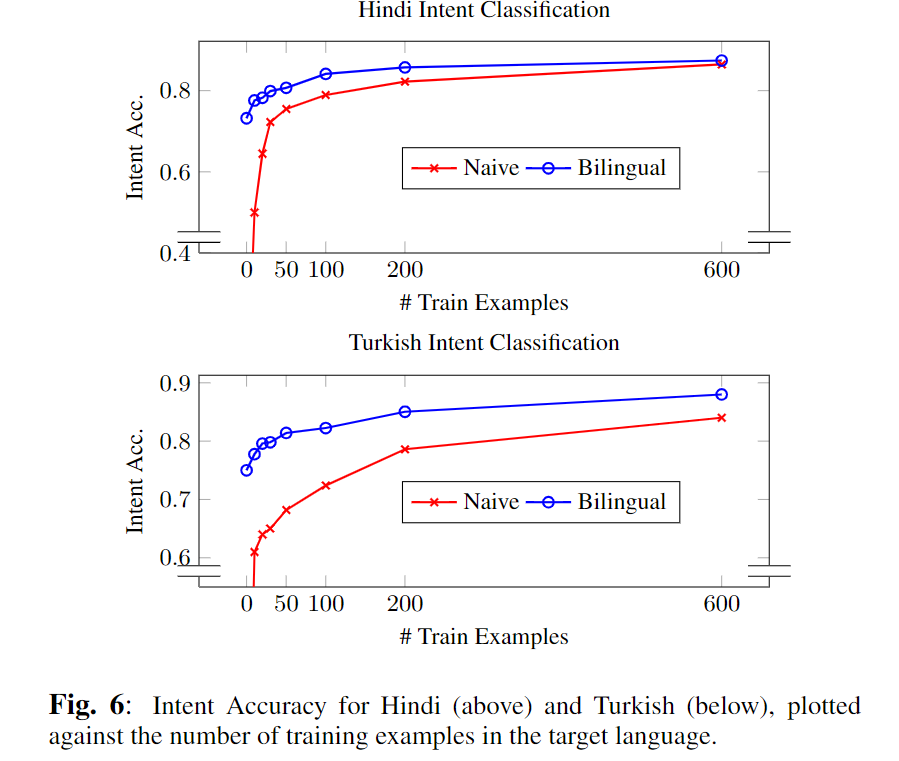 这里只比较了Naive的方法(只使用目标语言的数据,通过基础模型进行训练)和Bilingual方法(双语言混合训练的方法)。可以看到Naive需要600样本达到的水平,Bilingual方法在少于100样本时就能达到。
这里只比较了Naive的方法(只使用目标语言的数据,通过基础模型进行训练)和Bilingual方法(双语言混合训练的方法)。可以看到Naive需要600样本达到的水平,Bilingual方法在少于100样本时就能达到。
Slot-filling任务几个slot的结果分析:
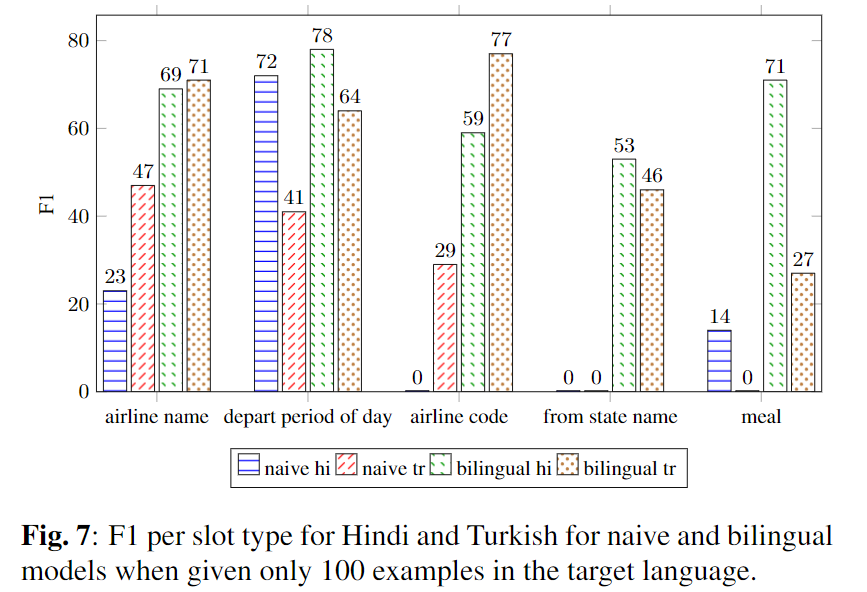 这里只使用100条目标样本。左边两个slot是高频slot,右边的三个slot是低频slot,可以看到bilingual方法相比naive方法在低频slot的识别效果上有更大的提升。
这里只使用100条目标样本。左边两个slot是高频slot,右边的三个slot是低频slot,可以看到bilingual方法相比naive方法在低频slot的识别效果上有更大的提升。